First-Of-Its-Kind LLM Benchmark Ranks Generative AI Against Real-World Business Tasks

LLM benchmarks evaluate how accurately a generative AI model performs, but most benchmarks overlook the kinds of real-world tasks an LLM would perform in an enterprise setting.

From MMLU to GLUE, the AI world suffers no dearth of LLM benchmarks. These important tools are designed to rigorously evaluate AI models like GPT-4 and Claude to determine which one generates more accurate outputs for a given task. Typically, that task revolves around something rather specific, like solving grade-school math problems, or coding in Python. While these kinds of tests yield valuable performance metrics used to rank LLMs, they’re not particularly illuminating for business users who simply need to understand whether an AI tool can handle real-world, day-to-day work.
At Salesforce AI Research, we recognized this shortfall as a serious obstacle for business users navigating their adoption of enterprise AI. To bridge this critical gap, we worked in collaboration with the AI Frontier team to develop the world’s first LLM benchmark purpose-built for generative AI applications in CRM. Simply put, this benchmark represents a first attempt at taking a truly scientific approach to validating large AI models against real-world business tasks – an approach that I hope will soon become ubiquitous in the enterprise world.
Quantifying enterprise value
Much of the attention around AI remains fixated on its superhuman versatility, often demonstrated by way of esoteric extremes – LLMs capable of rendering astronauts on horseback as easily as passing a state Bar exam. While these are no doubt impressive feats, enterprise customers care far more about focused deployments designed to do things that move the needle forward for their business in a fast, cost-effective way that can be understood analytically.
Unfortunately, despite the growing library of LLM benchmarks that target just about every conceivable task – writing essays, understanding math problems, even reasoning in the abstract – there’s still no clear way of answering the questions that matter most to business customers: how well will the LLM perform in an enterprise setting, especially in the context of applications as sensitive and mission-critical as CRM? It’s a blind spot that leaves decisionmakers in a tough spot. After all, how useful is a model’s LSAT score or culinary skill if it can’t reliably send your customers an email?
Salesforce delivers an AI first
Of course, curating an effective benchmark is no small feat, requiring a rare combination of expertise, resources, and access to data. Good benchmarks are specific enough to capture the unique needs of a particular domain, but broad enough to ensure that the results generalize. A high score shouldn’t simply mean that a model passed an arbitrary test in the lab; it should be a reliable indicator of how well the model will perform in the wild.
The Salesforce CRM Benchmark isn’t a proxy for understanding a model’s capabilities, but a direct line of sight, keeping a disciplined focus on the kinds of evaluations that give our customers peace of mind: prospecting, nurturing leads, as well as identifying sales opportunities and generating service case summaries.
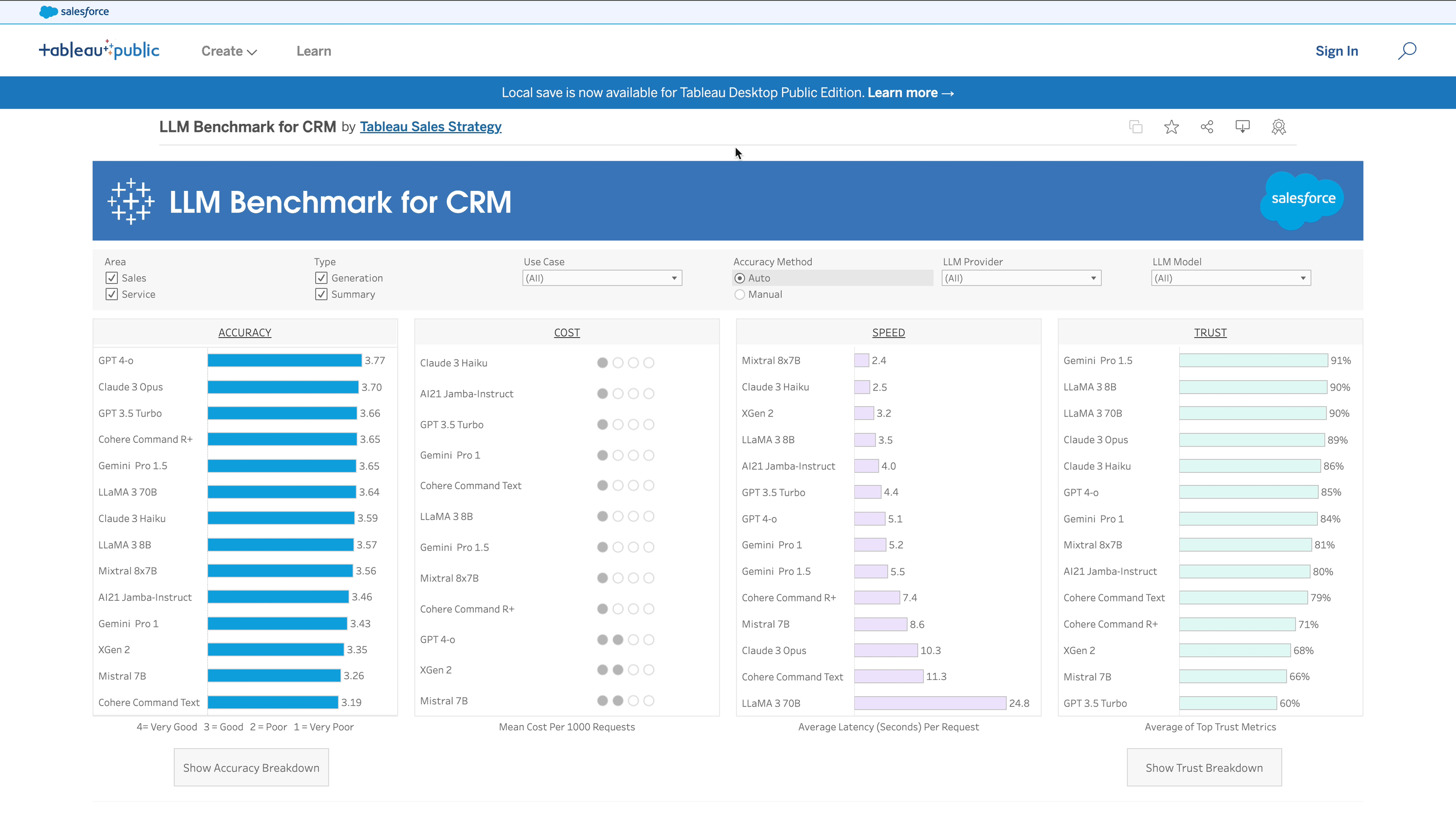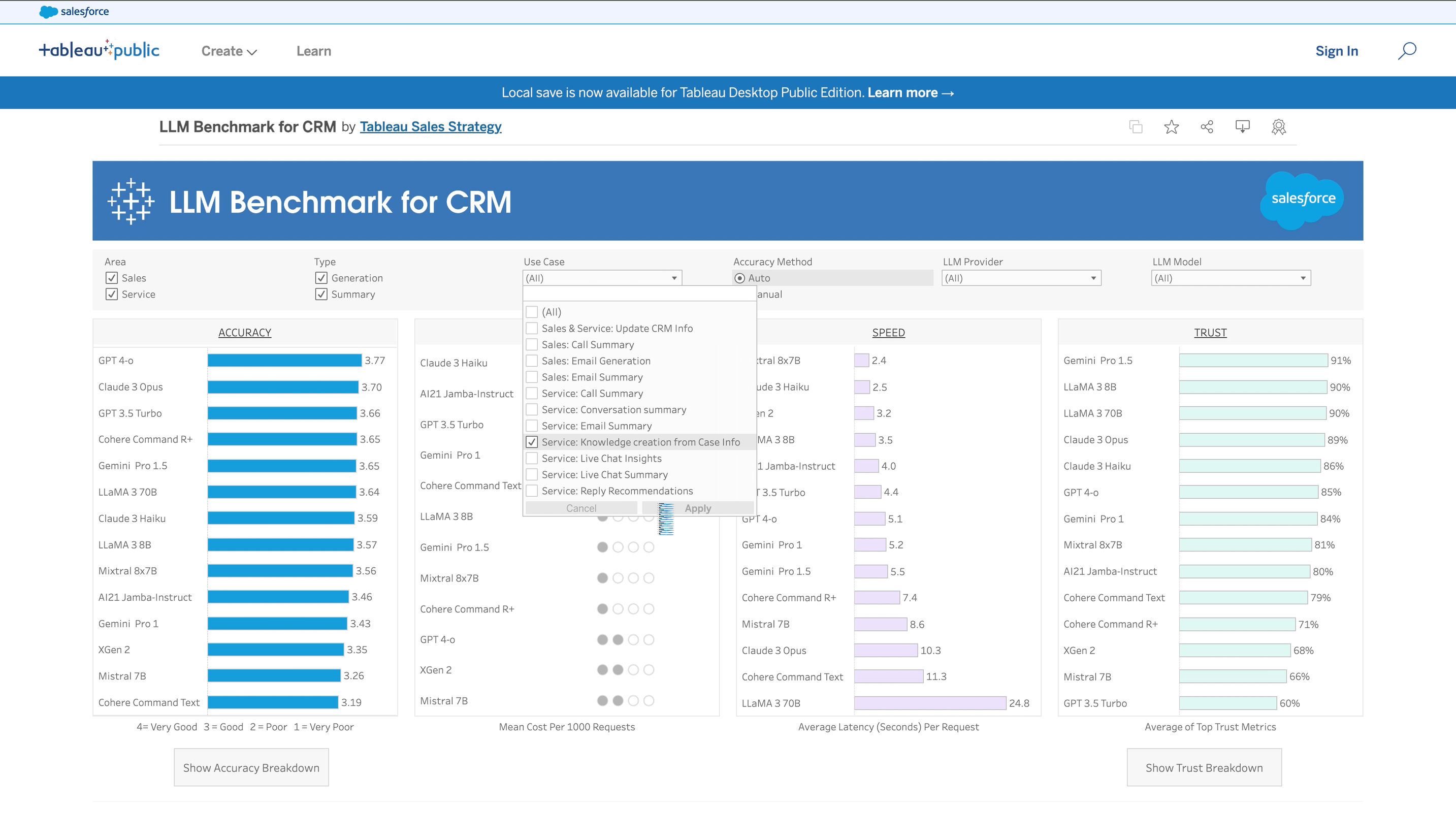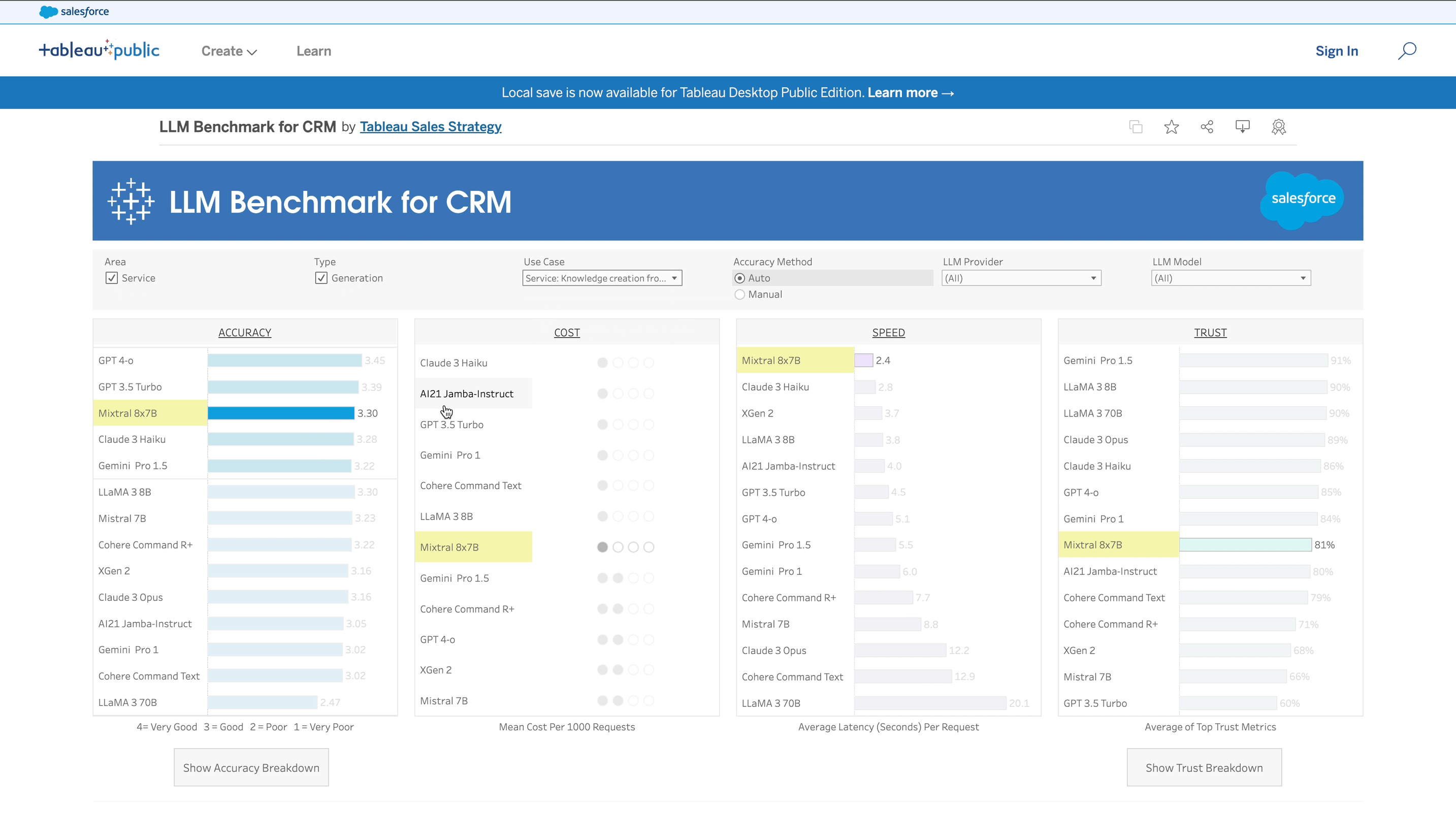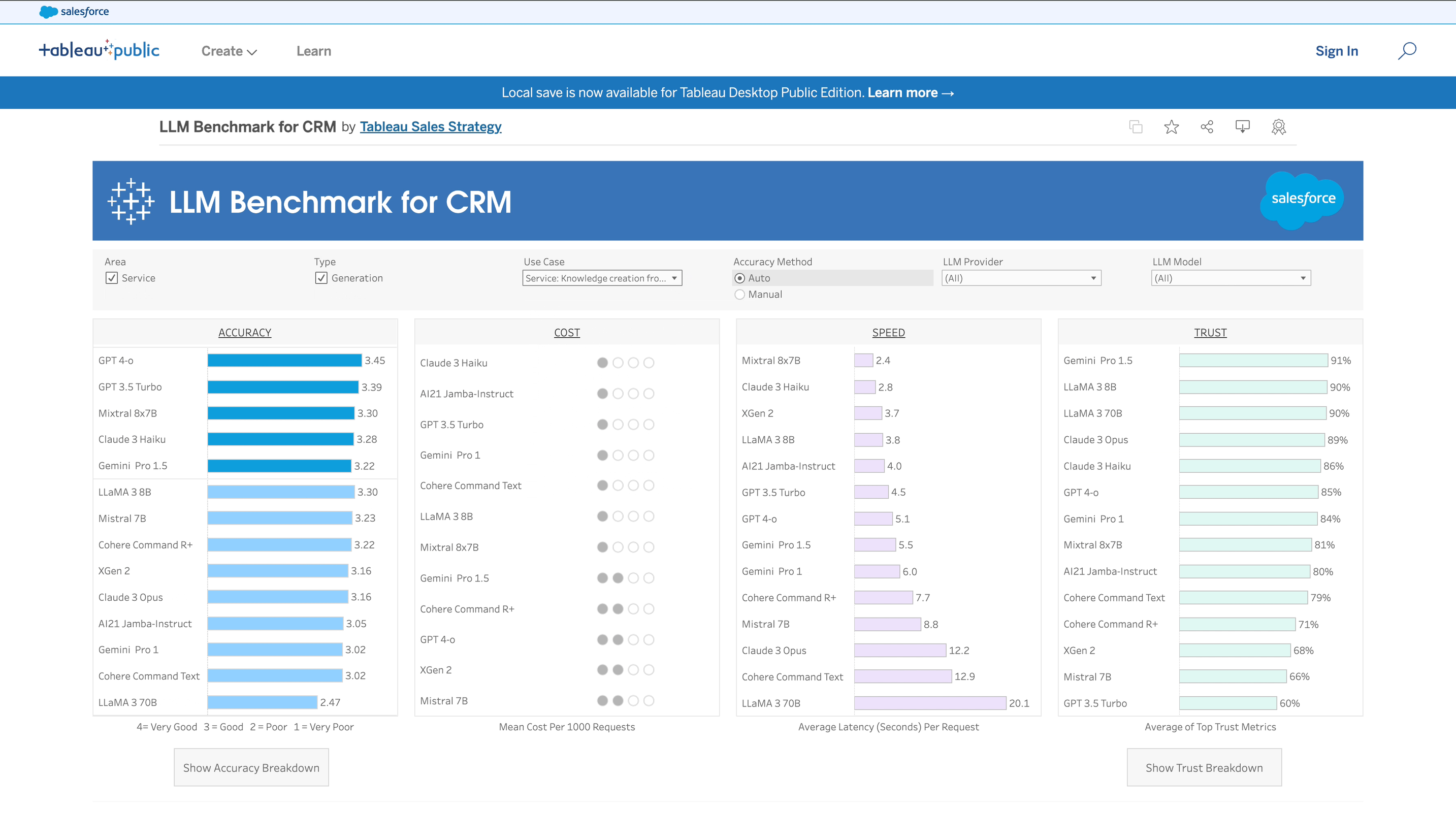
In developing our benchmark, the Salesforce AI Research team in collaboration with the AI Frontier team worked closely with enterprise Salesforce users across a range of industries and domains, working methodically to create a benchmark that evaluates a model’s performance based on the precise reality our customers face every day. In a sense, this benchmark was decades in the making, a direct product of our long-standing relationships with enterprise customers in every industry and on every continent.
In this regard, the central feature of this benchmark’s design wasn’t technological, but human. Throughout the process of curating its contents, we worked with human evaluators to ensure that their insights remained accurate and undiluted, enabling the benchmark to assess performance in metrics that an automated process can’t replicate. That human nuance informs every evaluation the benchmark runs – even for seemingly mundane tasks like transcript summaries, where deep familiarity with industry conventions and best practices can be the difference between a good transcript and one that misses the most important parts. This is a level of expertise even state-of-the-art LLMs aren’t likely to possess on their own.
What to read next




Next on the horizon
No matter how efficient or cost-effective, no business can benefit from AI it can’t trust. The Salesforce CRM Benchmark shines a light on a vibrant but often confusing space of possibilities, enabling businesses to make evidence-based decisions and identify the most useful solution for a given problem. In time, it will turn a dizzying array of possibilities – an entire world of constantly evolving bespoke models – into a simple recipe book that guides a new generation of LLM consumers with a straightforward rubric for evaluating speed versus capabilities versus trustworthiness.
It’s no exaggeration to say the Salesforce CRM Benchmark heralds a new, more illuminated era for enterprise AI. The business world has gone without such a tool for too long. But arming business users with better decision-making power is only the first step. Eventually, the same insights that allow us to better decide which AI models to deploy will shape the models themselves, empowering AI tools to autonomously select the best model for the job. In turn, this will make it easier and faster for humans to design next-generation deployments. As this practice of domain-specific benchmarking evolves, only the sky’s the limit.
Alex Varanese contributed to this story.



























