


Deep reinforcement learning (deep RL) is a popular and successful family of methods for teaching computers tasks ranging from playing Go and Atari games to controlling industrial robots. But it is difficult to use a single neural network and conventional RL techniques to learn many different skills at once. Existing approaches usually treat the tasks independently or attempt to transfer knowledge between a pair of tasks, but this prevents full exploration of the underlying relationships between different tasks.
When humans learn new skills, we take advantage of our existing skills and build new capabilities by composing and combining simpler ones. For instance, learning multi-digit multiplication relies on knowledge of single-digit multiplication, while knowing how to properly prepare individual ingredients facilitates cooking dishes with complex recipes.
Inspired by this observation, we propose a hierarchical RL approach which can reuse previously learned skills alongside and as subcomponents of new skills. It achieves this by discovering without human input the underlying hierarchical relations between skills. As the RL model executes a task, it breaks the task into smaller parts and eventually basic actions using a hierarchy of “policy networks,” or neural networks that predict actions, operating at different levels of abstraction. To represent the skills and their relations in an interpretable way, we also communicate all tasks to the RL agent using human instructions such as “put down.” This allows the agent in turn to communicate its plans and decisions using human language.

Figure 1 illustrates an example: given the instruction “Stack blue,” which represents a complex task, our model executes actions in a multi-level hierarchy to stack two blue blocks together. Steps from the top-level policy (i.e., the red branches) outline a learned high-level plan: “Get blue” (find and pick up one blue block) -> “Find blue” (Locate a second blue block) -> “Put blue” (Place the first block on the second). In addition, the components of this plan may themselves have hierarchical structure. Based on an intermediate-level policy, for instance, the task “Get blue” has two steps, “Find blue -> action: turn left,” whereas “Put blue” can be executed by a single action, “put down.”. Tasks accumulate progressively from lower to higher-level policies, while the higher level policy is said to “unfold” into smaller components.
Multi-task setting
We set up multiple object manipulation tasks on Minecraft games using Malmo platform. In each training episode, an arbitrary number of blocks with different colors (in total 6 colors in our experiments) are randomly placed in one of the two rooms. The agent is initially placed in one of the rooms. We consider a total of 24 tasks encoded with human instructions, including i) “Find x,” walking to the front of a block with color x, ii) “Get x,” picking up a block with color x, iii) “Put x,” putting down a block with color x, and iv) “Stack x,” stacking two blocks with color x together. We begin by training a policy for the lowest-level tasks, in this case “Find x,” then progressively increase the task set in stages.
Hierarchical policy network

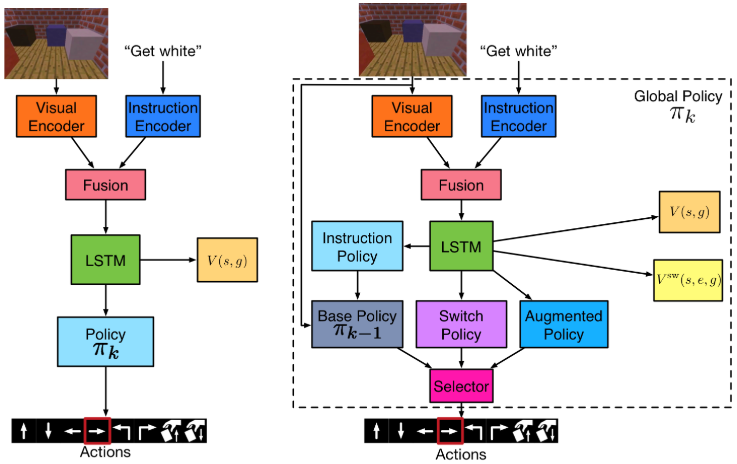
One of our key ideas is that at each stage, k, a new task in the current task set may be able to be decomposed into simpler subtasks, some of which are already executable by the policy at level k – 1. We would like each policy network in our model to discover this fact and make use of tasks already learned by the lower-level (“base”) policy whenever possible. Therefore, instead of using a flat policy (Figure 2a) that directly maps the agent’s internal representation of a game state and a human instruction to a primitive action, we propose a hierarchical design (Figure 2b) with the ability to reuse the base policy at level k – 1 to perform subtasks.
In particular, the “global” policy network at each level consists of four components, as shown in Figure 2b: a base policy for executing previously learned tasks, an instruction policy that manages communication between the global policy and the base policy, an augmented flat policy which allows the global policy to directly execute actions, and a switch policy that decides whether the global policy will primarily rely on the base policy or the augmented flat policy. The base policy is defined to be the global policy at the previous stage k – 1. The instruction policy maps the internal state and higher-level instruction to an instruction for a base task. The purpose of this policy is to inform the base policy which base tasks it needs to execute. The augmented flat policy maps state and task to a primitive action to ensure that the global policy is able to perform novel tasks that cannot be achieved merely by composing actions from the base policy. To determine whether to perform a base task or directly perform a primitive action at each step, the global policy further includes a switch policy that maps state and task to branch selection.
For details of the design and learning of the hierarchical policy, please refer to our paper.
Demo
Here we show a video demo of our trained agent performing various tasks in randomly generated environments by composing the hierarchical plans shown in real-time on the right. Duplicate subtasks occur because, if a sub-policy does not complete its task in the allotted time, the higher-level policy learns to repeat that subtask The agent has only partial observation (i.e., an “egocentric,” robot’s-eye view) and the top-down view in the demo is only for visualization. On the bottom of the agent view, we show the agent’s utterance generated by the top-level policy. Note that the environment of the last task in the demo was not seen during training.
Recommend turning on the audio while watching the demo video.
Citation credit
Tianmin Shu, Caiming Xiong, and Richard Socher. 2017.
Hierarchical and Interpretable Skill Acquisition in Multi-task Reinforcement Learning























