TL;DR: CodeT5+ is a new family of open code large language models (LLMs) with improved model architectures and training techniques. CodeT5+ achieves the state-of-the-art performance among the open-source LLMs on many challenging code…
TL;DR: LAVIS (short for LAnguage-VISion) is an open-source deep learning library for language-vision research and applications, offering comprehensive support for a wide range of tasks, datasets, and state-of-the-art models. Featuring a unified interface…
TL;DR: We propose ALPRO, a new video-and-language representation learning framework which achieves state-of-the-art performance on video-text retrieval and video question answering by learning fine-grained alignment between video regions and textual entities via entity…
TL;DR: BLIP is a new pre-training framework for unified vision-language understanding and generation, which achieves state-of-the-art results on a wide range of vision-language tasks. Background For a review of some terms and definitions…
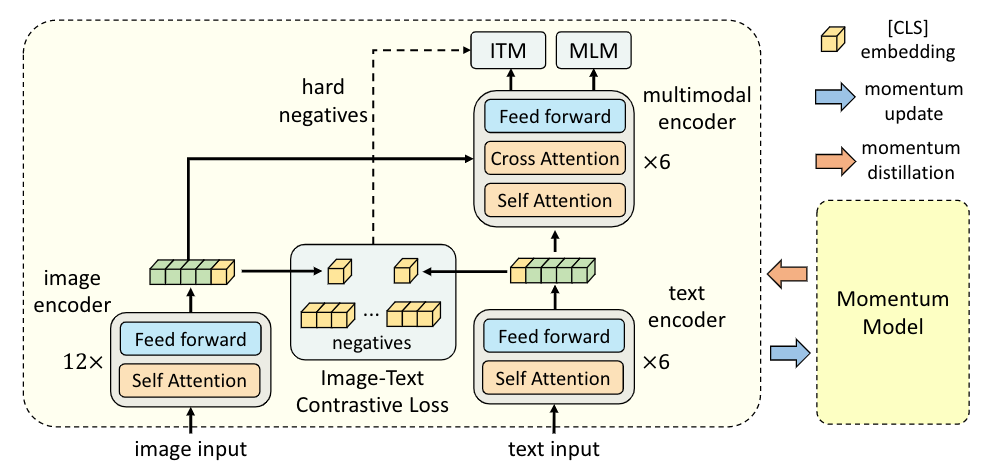
TL; DR: We propose a new vision-language representation learning framework which achieves state-of-the-art performance by first aligning the unimodal representations before fusing them. Vision and language are two of the most fundamental channels…
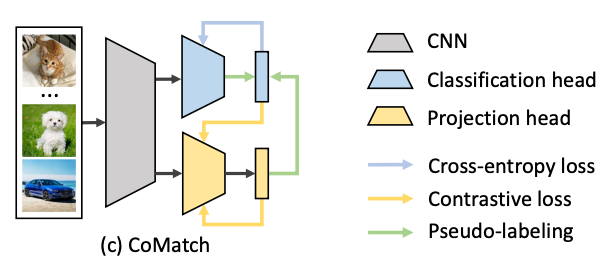
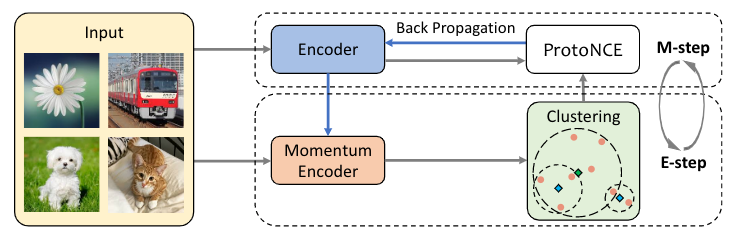
TL; DR: We propose a new semi-supervised learning method which achieves state-of-the-art performance by learning jointly-evolved class probabilities and image representations. What are the existing semi-supervised learning methods? Semi-supervised learning aims to leverage…
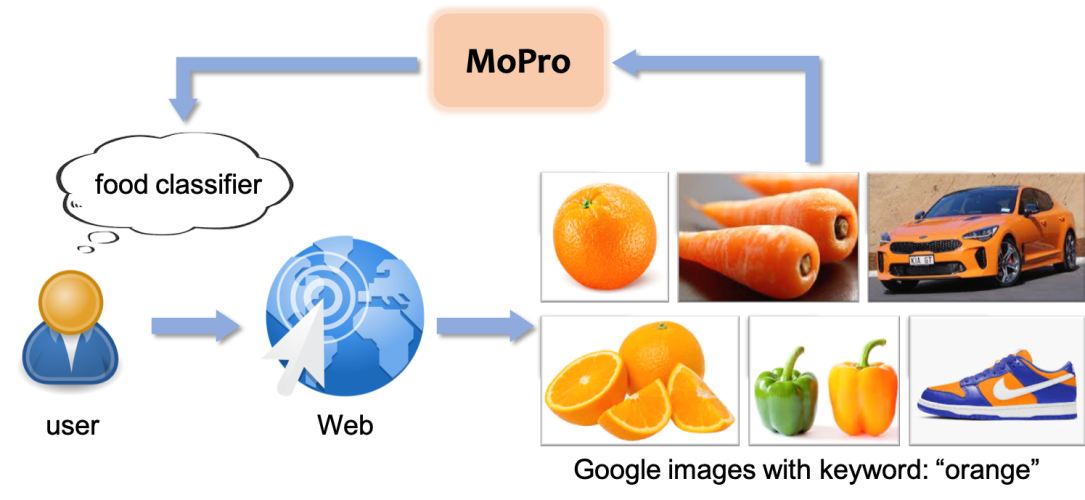
TL; DR: We propose a new webly-supervised learning method which achieves state-of-the-art representation learning performance by training on large amounts of freely available noisy web images. Deep neural networks are known to be…