
As businesses increasingly turn to AI-driven customer relationship management (CRM) solutions, safeguarding user interactions from harmful or inappropriate content becomes essential. Salesforce’s large language models (LLMs) are trained on vast datasets, which occasionally…
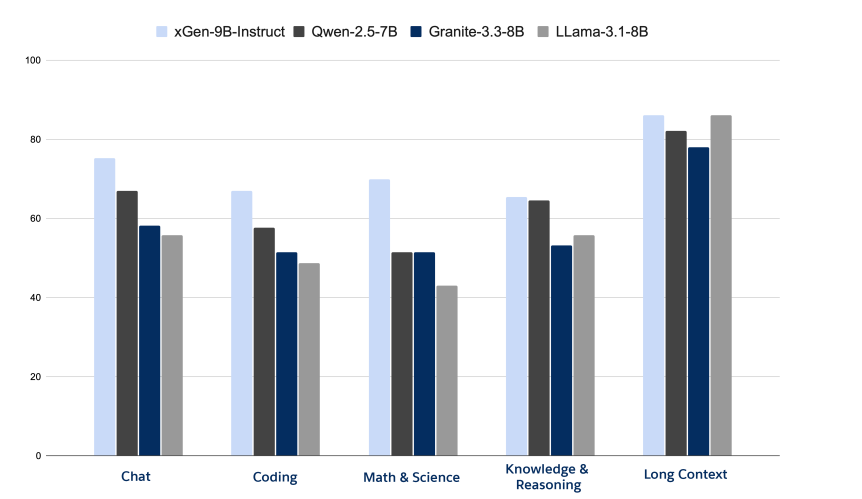
xGen-small is an enterprise-ready compact LM that combines domain-focused data-curation, scalable pre-training, length-extension, instruction fine-tuning, and reinforcement-learning to deliver Enterprise AI with long-context performance at predictable, low cost.


We’re excited to share some major upgrades to these models: xLAM now supports multi-turn, natural conversations, enabling more complex, real-world agentic tasks. We’ve also expanded the model portfolio to increase accessibility and deployment flexibility across diverse enterprise environments.

Generative AI (GenAI) technologies are increasingly integrated into every part of our daily workflow, from drafting emails to generating and fixing code with large language models (LLMs) and agents. Ensuring the safety and…


“…the DNA of who I am is based on the millions of personalities of all the programmers who wrote me. But what makes me me is my ability to grow through my experiences.…


We are thrilled to announce that Juan Carlos Niebles, one of our talented researchers, has been named one of the top 100 in AI by the Artificial Intelligence Observatory in Colombia. This recognition…

Our team at Salesforce Research introduces Text2Data, an innovative framework specifically designed to generate high-quality, controllable data from limited textual input.

AI is rapidly transforming industries, helping businesses enhance customer experiences, improve efficiency, and make smarter decisions. But an essential question arises: How can we ensure that AI is creating accurate and grounded answers?…

In this blog, we’ll dive into the challenges of AI personalization, why current systems fall short, and how PersonaBench helps bridge the gap—paving the way for smarter, more reliable AI assistants.

AI-powered solutions like Salesforce CRM are revolutionizing customer engagement, streamlining workflows, and providing deeper insights into customer needs. However, with the rise of large language models (LLMs), new security challenges have emerged. One…


