The WikiText language modeling dataset is a collection of over 100 million tokens extracted from the set of verified Good and Featured articles on Wikipedia.
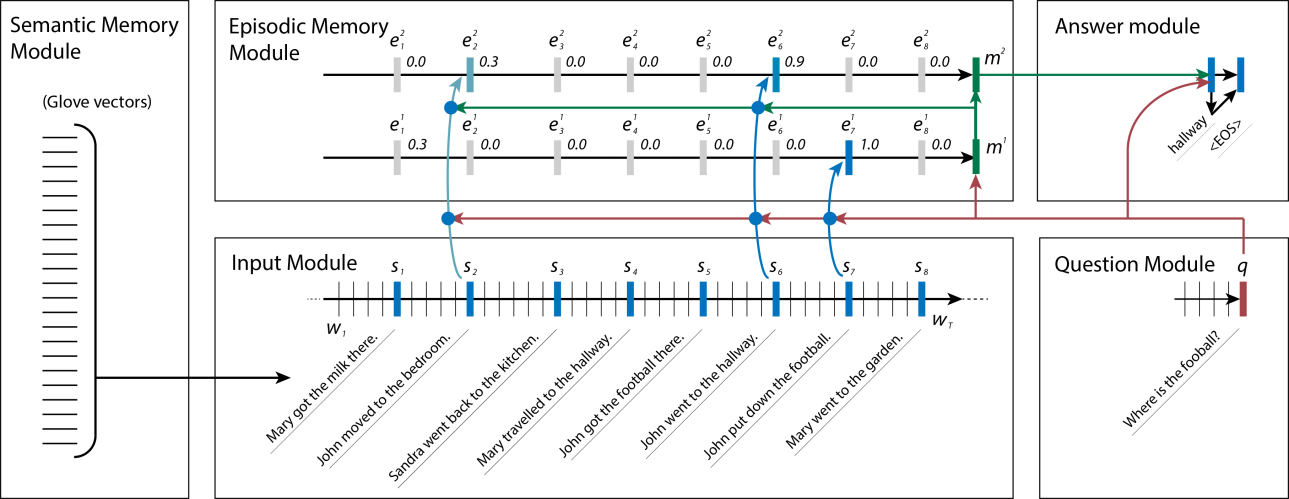
Today, we published new state of the art results on a variety of natural language processing (NLP) tasks. Our model, which we call the Dynamic Memory Network (DMN), combines two lines of recent work on memory and attention mechanisms in deep learning.