

Multi-domain DST and its evaluation problem
Dialogue state tracking (DST) is a backbone of task-oriented dialogue (TOD) systems, where it is responsible for extracting the user’s goal represented as a set of slot-value pairs (e.g., (area, center), (food, British)), as illustrated in figure below. The DST module’s output is treated as the summary of the user’s goal so far in the dialogue. It is then consumed by the subsequent dialogue policy component to determine the system’s next action and response. Hence, the accuracy of the DST module is critical to prevent downstream error propagation, affecting the success of the whole system.

We find that current studies on dialogue state tracking mainly operate with i.i.d. assumption, where training distribution of dialogues closely follow the test distribution. Due to this property of popular benchmarks, researchers consistently overestimate their model’s generalization capability. In line with this hypothesis, Table-1 demonstrates a substantial overlap of the slot values between training and evaluation sets of the MultiWOZ DST benchmark [1]. In Table-2 below, we observe that the slot co-occurrence distributions for evaluation sets tightly align with that of train split, hinting towards the potential limitation of the held-out accuracy in reflecting the actual generalization capability of DST models. Inspired by this phenomenon, we aim to address and provide insights into the following question: how well do state-of-the-art DST models generalize to the novel but realistic scenarios that are not captured well enough by the held-out evaluation set?
Our primary goal and approach significantly differ from the previous line of work:
- Our goal is to evaluate DST models beyond held-out accuracy.
- We leverage turn-level structured meaning representation (belief state) along with the dialogue context as conditions to generate user response without relying on the original user utterance.
- Our approach is entirely model-agnostic, assuming no access to DST models.
- Most importantly, we aim to produce novel but realistic conversation scenarios rather than intentionally adversarial ones.
Introducing our approach: CoCo-DST
To address the aforementioned limitations, we propose controllable counterfactuals (CoCo), a principled and model-agnostic approach to generate novel conversation scenarios. Our approach is inspired by the combination of two natural questions: how would DST systems react to (1) unseen slot values and (2) rare but realistic slot combinations?
How does CoCo-DST work?
As illustrated in the figure below, CoCo-DST consists of three major steps:
- Counterfactual goal generation: Given a dialogue and a particular user turn, CoCo-DST generates a counterfactual goal by stochastically dropping or adding slots followed by replacing slot values sampled from a dictionary.
- Counterfactual conversation generation: Conditioning on the counterfactual goal and the past dialogue turns, CoCo-DST decodes K candidate user utterances via beam search.
- Filtering low-fidelity generations: Finally, starting from the top of the generated candidate list, we apply two filtering strategies: (i) Slot-value match filtering tackles the degeneration issue where the generated utterance misses at least one value from the goal, (ii) Slot-classifier filtering tackles the overgeneration issue by eliminating CoCo-generated utterances mentioning slot types that are not part of the counterfactual goal.

We cast the actual utterance generation as a conditional language modeling, where the input is the linearized sequence of dialogue context and turn-level dialogue state and the output is the user utterance. This formulation allows us to plug-in a pre-trained encoder-decoder architecture [2] as the backbone that powers the counterfactual conversation generation. We also propose a filtering strategy based on slot-value match and slot-type classification to eliminate utterances that fail to perfectly reflect the counterfactual goal due to degeneration or overgeneration.
Example Novel Scenarios Generated by CoCo-DST
In Figures 3-8 below, we demonstrate several conversation scenarios generated by CoCo-DST to illustrate our pipeline through different meta operations. We first decode possible conversations using beam search. We then apply filtering, which strikes-through the invalid candidates (colored in red). Among the remaining valid options (colored in orange), the top ranked candidate (colored in green) is selected.
Add a slot: restaurant-book people-4

Drop a slot: restaurant-food-indian
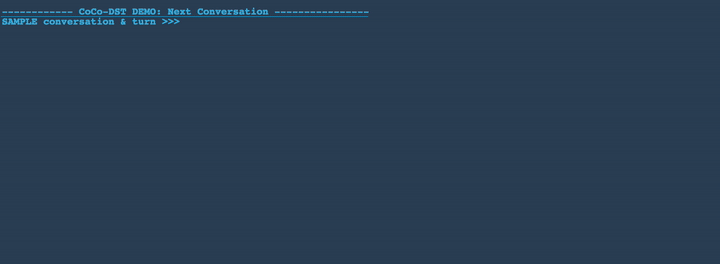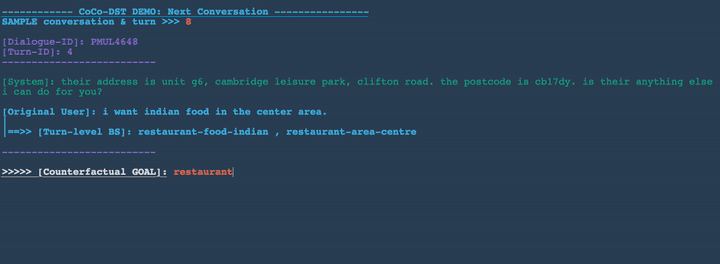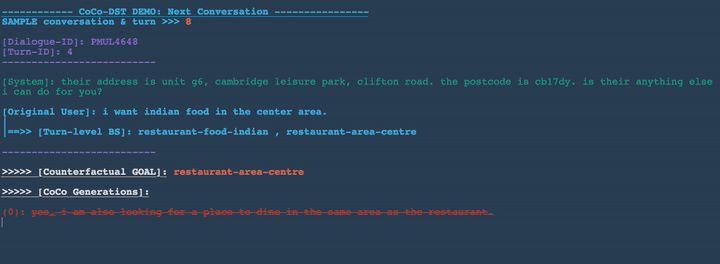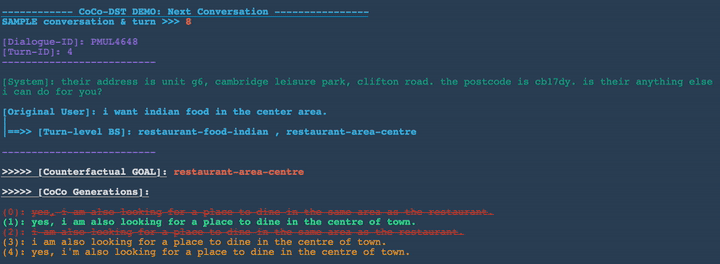
Change slot values: restaurant-food-chinese , restaurant-area-north
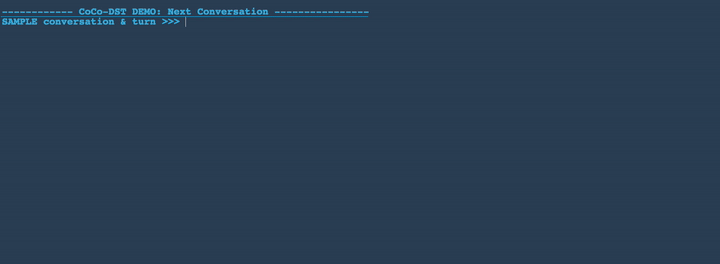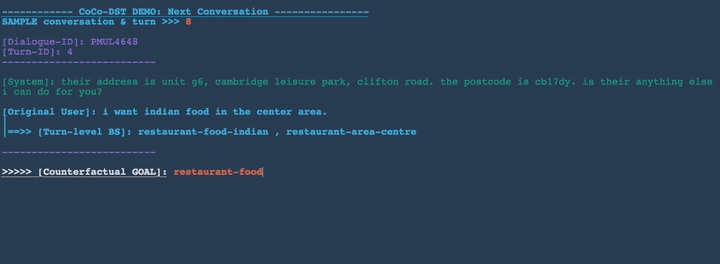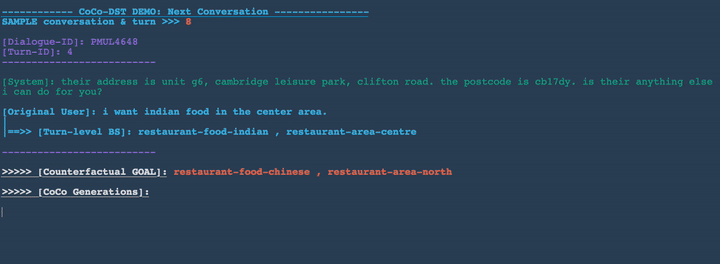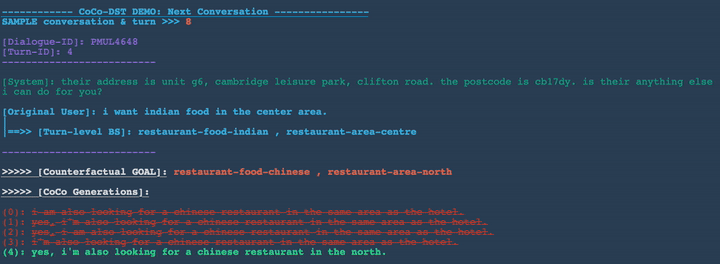
Combine meta operations:
- Drop restaurant-area, restaurant-food
- Add restaurant-book people-8 , restaurant-book day-friday, restaurant-name-black sheep
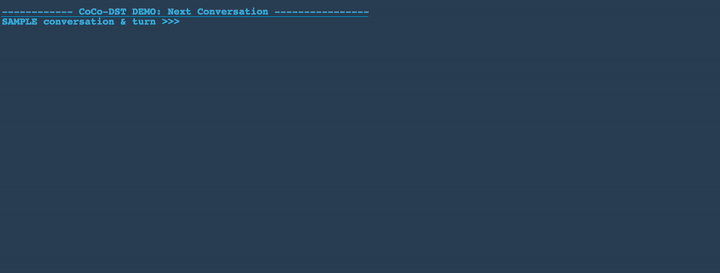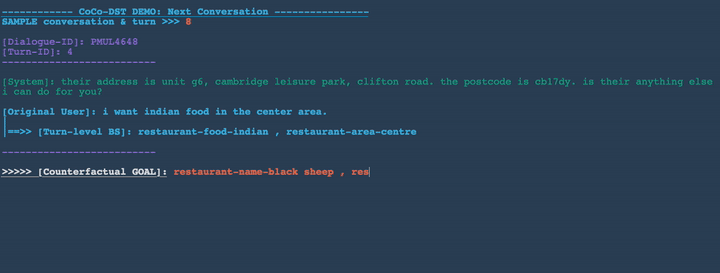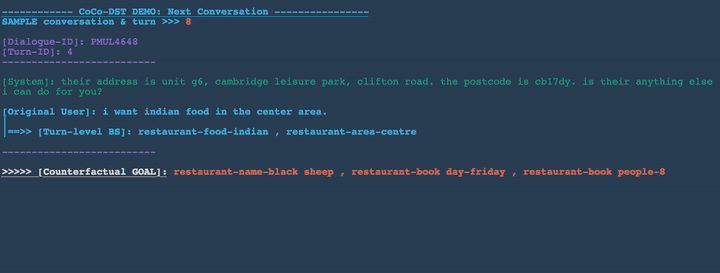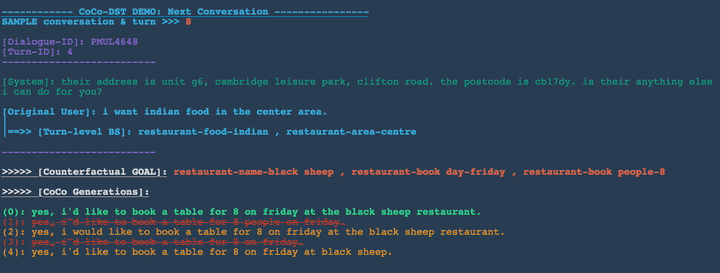
Unseen domain generalization:
- flight-destination-san francisco , flight-departure-new york
- flight-book people-6 , flight-book day-sunday
Evaluating SoTA DST models with CoCo-DST
We generate a test set consisting of new conversation scenarios derived from the original evaluation data of MultiWOZ using different slot-value and slot-combination dictionaries. This allows us to investigate and discuss the generalization capabilities of the DST models from different angles below.
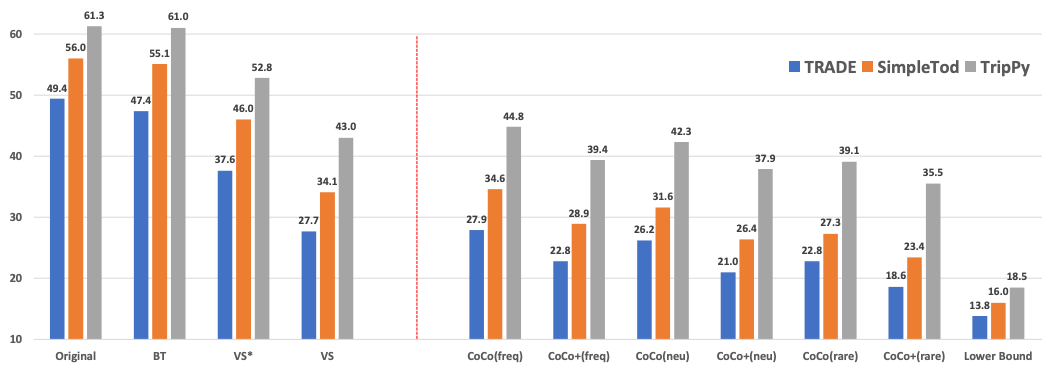
Unseen Slot-Value Generalization: We analyze the effect of unseen slot values using in-domain (I) and out-of-domain (O) value dictionaries compared to the original set of slot values that have large overlap with the training data. Results presented on the left part of the figure above show that the performance of DST models significantly drops (by up to 11.8%) compared to original accuracy even on the simple counterfactuals generated by value-substitution (VS*) strategy using in-domain unseen slot-value dictionary (I). Furthermore, using out-of-domain slot-value dictionary (O) results in about 10% additional drop in accuracy consistently across the three models. Consistent drop in accuracy suggests that strong DST models Trade [3], SimpleTOD [4], and TripPy [5] are all similarly susceptible to unseen slot values.
Generalization to Novel Scenarios: The right section of figure above presents the main results in our effort to answer the central question we posed at the beginning. Based on these results, we see that state-of-the-art DST models are having a serious difficulty generalizing to novel scenarios generated by our proposed approach using frequent, neutral, and rare slot combination strategies. The performance drop consistently increases as we start combining less and less frequently co-occurring slots (ranging from freq to rare) while generating our counterfactual goals. In particular, CoCo+(rare) counterfactuals drops the accuracy of TRADE from 49.4% to 18.6%, pushing its performance very close to its lower bound of 13.8%. Even the performance of the most robust model (TripPy) among the three drops by up to 25.8%, concluding that held-out accuracy for state-of-the-art DST models may not sufficiently reflect their generalization capabilities.
Transferability Across Models: A significant difference and advantage of our proposed approach lies in its model-agnostic nature, making it immediately applicable for evaluation of any DST model. As can be inferred from Figure-9, the effect of CoCo-generated counterfactuals on the performance is consistent across the three DST models. This result demonstrates the transferability of CoCo, strengthening its reliability and applicability to be generally employed as a robustness evaluation of DST models by the future research.
Retraining with CoCo-generated conversations
All three DST models are consistently most susceptible to conversations generated by CoCo+(rare). This leads us to seek an answer for the following question: Would using conversations generated by CoCo+(rare) to augment the training data help mitigate the weakness against unseen slot values and/or novel scenarios?
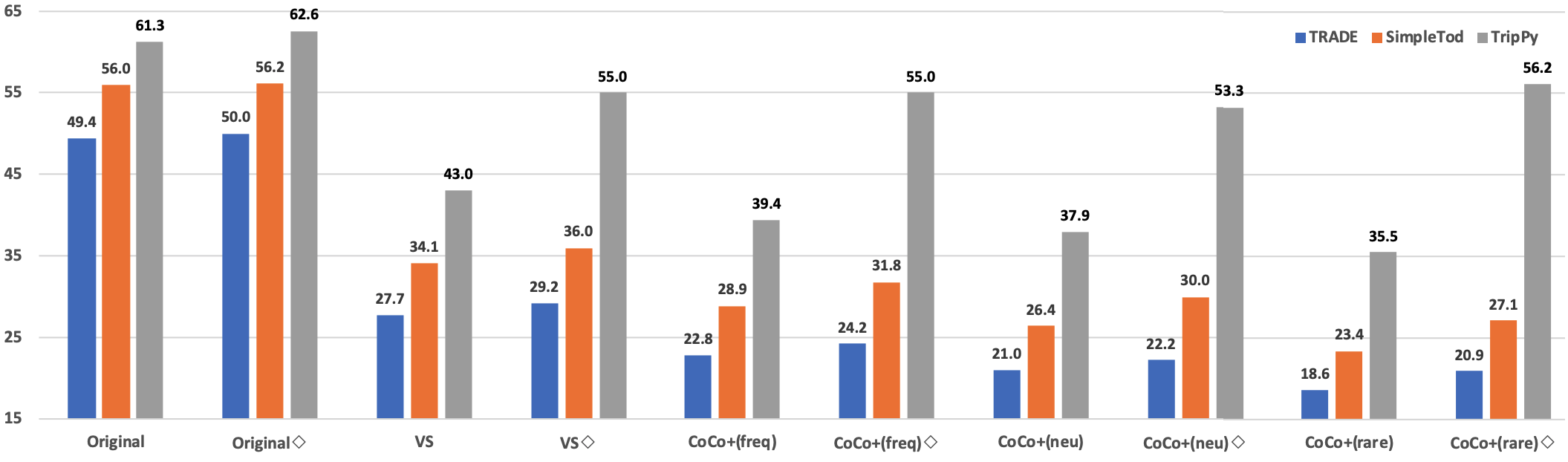
To address this question, we first retrain each DST model on the MultiWOZ training split combined with conversations generated by CoCo+(rare). Retrained DST models are then evaluated on both the original and counterfactual test sets. In the figure above, we show that this strategy improves the robustness of all three DST models across the board. Most notably, this data augmentation strategy rebounds the performance of TripPy from 35.5% to 56.2%, significantly closing the gap with its performance (61.3%) on the original held-out test set. We also observe that retrained DST models obtain an improved joint goal accuracy on the original test set, further validating the quality of CoCo-generated conversations. Finally, we would like to highlight that retrained TRIPPY model achieves 62.6% joint goal accuracy, improving the previous state-of-the-art by 1.3%.
CoCo as Data Augmentation (CoCoAug)
We also conduct a preliminary study on exploring CoCo as a data augmentation strategy. We experiment with {1, 2, 4, 8} times data augmentation size over original training data on TripPy following its own default cleaning so that results with previous methods are more comparable.
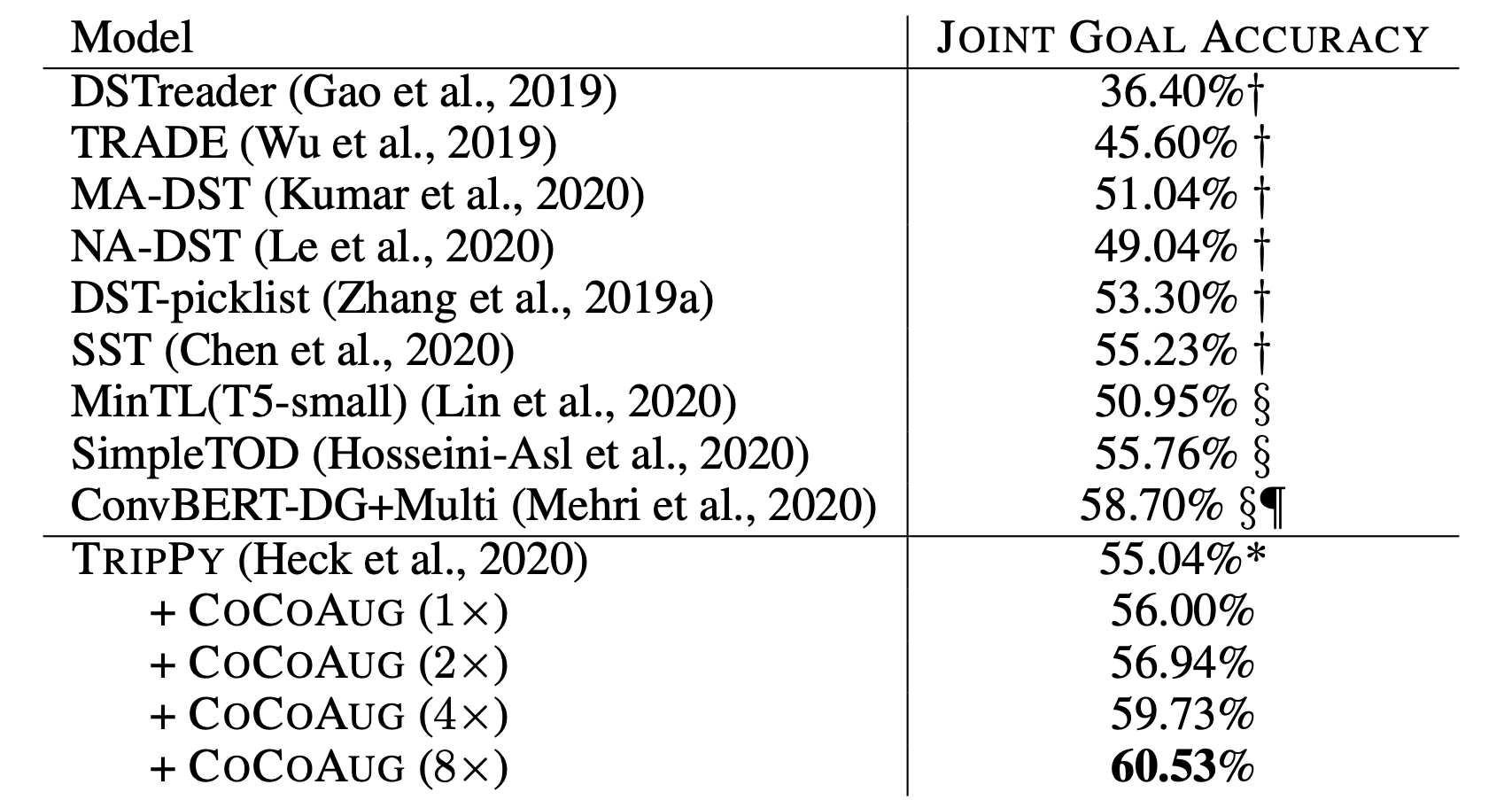
In the above table, we present the results of our experiments in comparison with several baselines trained only with original MultiWOZ data. TripPy significantly benefits from additional conversations generated by CoCo and its performance consistently increases as the size of augmented data grows. In particular, using 8x data augmentation produced by CoCo provides 5.5% improvement for TripPy over its counterpart without data augmentation. We leave the exploration of how to fully harness CoCo as a data augmentation approach for future work.
Human Evaluation
We next examine the quality of CoCo-generated conversations from two perspectives: human-likeness and correctness. The first metric evaluates whether a user utterance is fluent and consistent with its dialog context. With correctness, we aim to evaluate whether the generated utterance perfectly reflects the underlying user goal.
We can see that the human evaluators find CoCo-generated utterances (ori) w.r.t the original user goal as more human-like and correct than the original user utterances written by humans. CoCo(ori) and CoCo(freq) are found to be difficult to distinguish from the original human utterances, while the other two variants lead to slightly less human-like generations, but the gap is not large in either cases. All three variants of the CoCo-generated conversations significantly outperform the human-written examples in terms of how correctly they reflect the underlying user goals. These results demonstrate the effectiveness of our proposed approach in generating not only high-fidelity but also human-like user utterances, proving its potential to be adopted as part of robustness evaluation of DST models.
What’s next?
We have demonstrated the power of CoCo-DST in more robustly evaluating and improving the generalization capability of SoTA DST models. We conclude that SoTA DST models have difficulty in generalizing to novel scenarios with unseen slot values and rare slot combinations, confirming the limitations of relying only on the held-out accuracy. We hope that CoCo-DST encourages and inspires further research on how to develop more robust task-oriented dialogue systems by paying more attention on the evaluation of the proposed models, which is quite essential to deployment of these models. If you are interested in learning more, please check out our paper/code and feel free to contact us at syavuz@salesforce.com
Resources
- Paper: CoCo: Controllable Counterfactuals for Evaluating Dialogue State Trackers (accepted to ICLR 2021)
- Code: https://github.com/salesforce/coco-dst
When referencing this work, please cite:
@article{li-yavuz2021coco, title={CoCo: Controllable Counterfactuals for Evaluating Dialogue State Trackers}, author={Shiyang Li and Semih Yavuz and Kazuma Hashimoto and Jia Li and Tong Niu and Nazneen Rajani and Xifeng Yan and Yingbo Zhou and Caiming Xiong}, journal={arXiv preprint arXiv:2010.12850}, year={2021} }
References
[1] Budzianowski et al., MultiWOZ – A Large-Scale Multi-Domain Wizard-of-Oz Dataset for Task-Oriented Dialogue Modelling (EMNLP 2018)
[2] Raffel et al., Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (JMLR 2020)
[3] Wu et al., Transferable Multi-Domain State Generator for Task-Oriented Dialogue Systems (ACL 2019)
[4] Hosseini et al., A Simple Language Model for Task-Oriented Dialogue (NeurIPS 2020)
[5] Heck et al., TripPy: A Triple Copy Strategy for Value Independent Neural Dialog State Tracking (SIGdial 2020)
[6] Eric et al., MultiWOZ 2.1: A Consolidated Multi-Domain Dialogue Dataset with State Corrections and State Tracking Baselines (LREC 2020)























