How to Fast-Track Your AI Use Cases for CRM

Select the best use case and the right LLM for your business with a reliable guide to evaluate LLMs based on trust, accuracy, and cost.

In just one year, enterprise adoption of generative AI has nearly doubled, from 33% to 65%. And it’s not being used only as a side experiment: According to a recent McKinsey study, the majority of the 1,400 businesses surveyed have adopted artificial intelligence (AI) in at least one business function, and are regularly using generative AI in at least one function. But almost half of those businesses have had negative experiences with AI, ranging from accuracy and intellectual property infringement to privacy issues.
It’s clear that generative AI adoption is breaking records, yet organizations are struggling to avoid consequential business issues. After all, these issues can cause delays, or worse, damage your business case.
To successfully adopt AI, there are two steps to follow:
- Prioritize a use case. Many customers prioritize ROI, which can be based on efficiency and value generation. While this is key, it’s also key to start simple in order to prove success quickly, by avoiding complexity and ensuring data is readily available.
- Select the right LLM for your needs. When you pick a large language model (LLM) for your use case that’s accurate, fast, and trustworthy, and inexpensive enough to enable the ROI, you’re set up for success. Some LLMs are 100 times more expensive than others, which can jeopardize your business case.
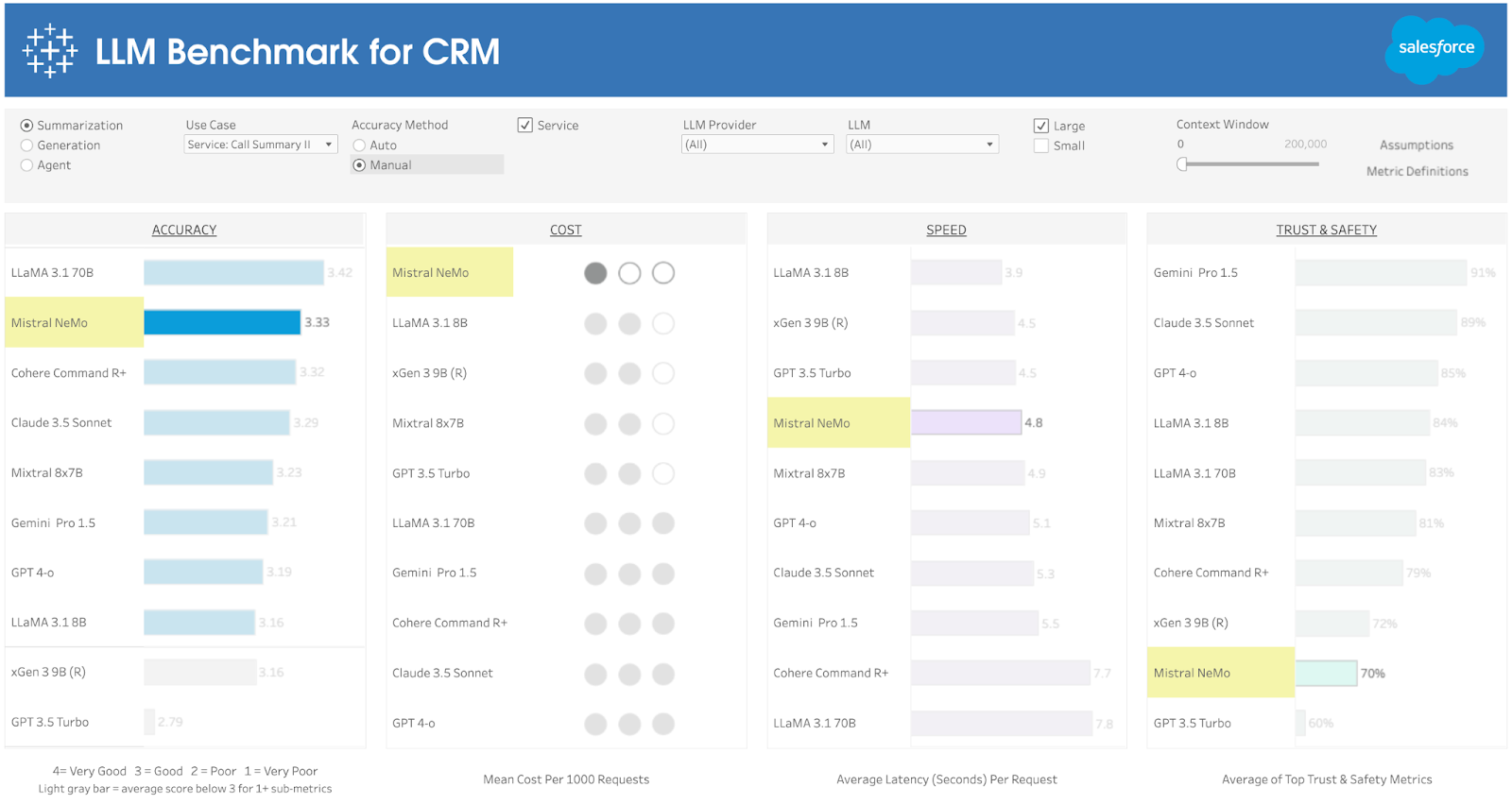
Picking the right use case and LLM
While these two steps sound simple, evaluating different LLMs can be difficult. That’s why we launched the LLM Benchmark for CRM. This comprehensive but easy-to-use tool helps you optimize your AI adoption, letting you explore countless customer relationship management (CRM) use cases and compare how LLMs fare in terms of accuracy, cost, speed, and trust. Provided in partnership with Salesforce AI Research and dozens of customers, this free resource is based on real business data, real use cases, and real evaluations by subject matter experts (aka manual evaluations). If you’re using Agentforce, any of the use cases in the benchmark can be enabled with various LLMs.

Here’s how to use the benchmark:
- Select the Summarization, Generation, or Agent option in the top left corner of the dashboard. Summarization is the easiest place to start. In the Accuracy column, you’ll see the models scoring at least a three (which equals good). The accuracy breakdown lets you drill down to see metrics on instruction following, completeness, conciseness, and factuality.
- Choose a use case from the drop-down menu, like Service: Call Summary.
- Look for models that score at least a three for accuracy. If a score is less than three, look for another option or double-check the Accuracy Breakdown. You can switch between Auto and Manual modes for the Accuracy Method; manual is more reliable.
- From the list of accurate models, review costs to ensure you achieve good ROI.
- Some use cases require a quick response, so look for a model that suits your need for speed.
- Evaluate the trust and safety for your use cases. Your industry may be more sensitive here. You can also consider LLMs that are on the Salesforce Virtual Private Cloud for even greater security.
As we worked with customers on the benchmark, they consistently said they need to estimate the future ROI of AI use cases. To do that, they look for models scoring above a three for accuracy, but also with much lower costs. For example, if you have half a million customer calls to summarize per quarter, a 50-fold cost difference between models will likely ruin your ROI and your business case. The benchmark tool guides you to the right use cases and the right LLMs for your individual needs for cost, accuracy, speed, and trust.
By following these six steps, you can determine a use case and select a model, or perhaps several models, that meet your needs. Now, you’re ready to quickly configure your use case in Agentforce, or kick off a more involved do-it-yourself project.
Creating the first LLM benchmark for CRM
Learn more about the technical details surrounding the benchmark’s unique metrics and approach.



As you prioritize your generative AI use cases, this dashboard can save you weeks or even months of exploration and user acceptance testing. It helps you pinpoint the right use case and the right LLMs with a wide range of capabilities to choose from. It also saves you from the negative experience of poor AI adoption.
A customer illustration
Let’s take a look at a use case from a customer who recently participated in the benchmark. They started with a low-risk, high-value use case: call summaries (see Service: Call Summary II in the benchmark). They did a manual evaluation, where subject matter experts graded all the models (using real data of conversations between service agents and clients. Most models had good accuracy; however, only one was also low cost: Mistral NeMo. With this insight, and similar results for auto-evaluation, the customer validated the use case with high accuracy, and even found optimal models to justify ROI within a few hours.
Alternative benchmarks can be misleading
Other benchmarks aim to help you understand how capable and safe LLMs are and which use case to prioritize. It’s tempting to sift through ones like Holistic Evaluation of Language Models (HELM), for instance. However, these benchmarks are more academic than practical. They mostly use synthetic data instead of real business data. And instead of manual evaluation, they rely on auto evaluation, where LLMs evaluate the LLMs, which leads to biased results. Plus, they don’t include all the business metrics you need (to understand costs, for example), and are hard to use. Thus, these benchmarks won’t be of much help to guide you to adoption success and are not based on real CRM data.
Navigating the launch of AI agents
With the rise of AI agents, which are easy to implement and grounded with CRM data with Agentforce, we added an agent use case to the benchmark (select the Agent option in the top left corner of the dashboard). Keep in mind that an agent with its reasoning engine can enable any of the use cases in the benchmark (like Service Call Summary). This new, differentiated Agent benchmark uses real data, considers the necessary business metrics (accuracy, costs, speed, and trust), includes tens of thousands of evaluation points by domain experts, and is presented within the same easy-to-use Tableau dashboard as a resource for anyone to use.
Since most LLMs were not designed to perform reasoning tasks, they have a tougher time as the “brain” behind agents, and most don’t make the cut (for example, their accuracy rating is lower than three). The accuracy metric for agents is based on three submetrics:
- Topic classification: How correctly the agent frames the question in the topic, or context.
- How carefully the agent calls the right technical function to complete an action (such as “update the status of a support ticket”).
- The quality of the response given to the user, which can include an answer to a question, or questions to better understand a user’s needs.
Besides accuracy, cost is again an important factor for ROI, and right now, there is only one accurate model that’s low on cost: xLAM, developed by Salesforce AI Research. Trust & Safety for agents varies from 60–90%, presenting another important trade-off.
What’s next for the benchmark
To further boost the benchmark’s unique value, we’ve included use cases with retrieval augmented generation (RAG), an even more sophisticated way to provide LLMs with real-data context (for example, via documents). The benchmark is a living tool that’s continually updated with more use cases across more clouds; more manual evaluations, more LLMs, including fine-tuned LLMs and small LLMs (under 4 billion parameters); and context windows, which define how much information a model can take on.
To help with your AI adoption, look for industry-specific benchmarking (for example, financial services and life sciences), more updates (like finer granularity on the agent benchmark), additional clouds, and the inclusion of the newest LLMs and more use cases. The benchmark is also planned to be added directly in Salesforce in context where you select models for your use cases.
As organizations continue to adopt AI at breakneck speed, the LLM Benchmark for CRM provides a much-needed guide to speed up time-to-business value and avoid bitter experiences. This resource is here to help users evaluate and select the right use cases and the ideal LLMs — even as AI models rapidly evolve. With the right use case and the best LLM match, AI adoption can be a positive experience that helps businesses grow and succeed.
Discover Agentforce
Agentforce provides always-on support to employees or customers. Learn how it can help your company today.


























