MINT-1T: Scaling Open-Source Multimodal Data by 10x: A Multimodal Dataset with One Trillion Tokens

We are excited to open-source 🍃MINT-1T, the first trillion token multimodal interleaved dataset and a valuable resource for the community to study and build large multimodal models.


This work was done in collaboration with many other great co-authors: Oscar Lo, Manli Shu, Hannah Lee, Etash Kumar Guha, Matt Jordan, Sheng Shen, Mohamed Awadalla, Silvio Savarese, Yejin Choi, and Ludwig Schmidt.
We are excited to open-source 🍃MINT-1T, the first trillion token multimodal interleaved dataset and a valuable resource for the community to study and build large multimodal models.
Background

Multimodal interleaved documents are sequences of images interspersed in text. This structure allows us to train large multimodal models that can reason across image and text modalities. Some of the most capable multimodal models like MM1, Chameleon, and Idefics2 have shown the importance of training on interleaved data to attain best performance.
Building MINT-1T

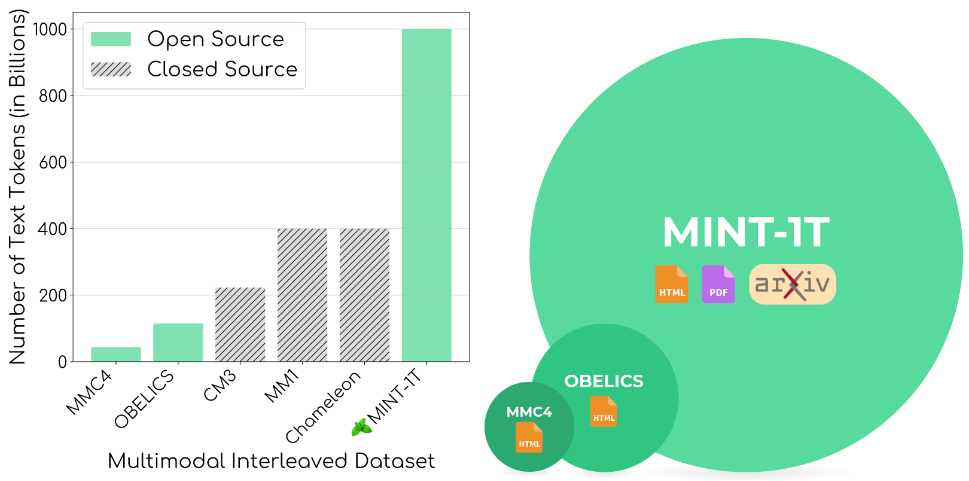
Our key principles behind curating 🍃MINT-1T are scale and diversity. While previous open-source datasets such as OBELICS and MMC4, where at most 115 billion tokens, we collect 1 trillion tokens for 🍃MINT-1T allowing practitioners to train much larger multimodal models. To improve the diversity of 🍃MINT-1T we go beyond HTML documents, and include web-scale PDFs and ArXiv papers. We find that these additional sources improve domain coverage particularly on scientific documents.
Model Experiments

We validate 🍃MINT-1T by pre-training XGen-MM multimodal models (sampling 50% of tokens from HTML documents and the rest from PDFs/ArXiv). We evaluate our models on captioning and visual question answering benchmarks. We find that 🍃MINT-1T outperforms the previous leading multimodal interleaved dataset, OBELICS!
Future Work
We are already training our new iteration of XGen-MM models on 🍃MINT-1T and we are excited to continue to share some of the best open-source datasets and models with the community. Stay tuned for more!
Explore More
Salesforce AI invites you to dive deeper into the concepts discussed in this blog post (links below). Connect with us on social media and our website to get regular updates on this and other research projects.
- Dataset
- Paper
- Salesforce AI Research Website
- Follow us on X (Previously Twitter): @SFResearch, @Salesforce
Acknowledgments
A big thank you to the infrastructure team, Srinath Reddy Meadusani and Lavanya Karanam, for their tremendous work and Paul Josel for helping us with figure design.


























