



Retrieval Augmented Generation (RAG) has not only gained steam as one of the most invested areas of research in generative AI but also gathered considerable popularity and commercialization opportunities. RAG is typically applied to question-answering problems, where certain external contextual information retrieved from a data source (potentially private) is provided as part of the question and the generated answer is expected to be factually grounded on the contextual clues. RAG features a retriever, which retrieves relevant knowledge, and a large language model (LLM) that generates an answer faithfully or recognizes if the contextual content is irrelevant or contradicting.

At Salesforce AI Research, we understand the importance of faithfulness and accuracy when building RAG systems that rely heavily on the performance of the LLM. Thus, we introduce SFR-RAG, a 9-billion-parameter language model trained with a significant emphasis on reliable, precise, and faithful contextual generation abilities specific to real-world RAG use cases and relevant agentic tasks. They include precise factual knowledge extraction, distinguishing relevant against distracting contexts, citing appropriate sources along with answers, producing complex and multi-hop reasoning over multiple contexts, consistent format following, as well as refraining from hallucination over unanswerable queries.
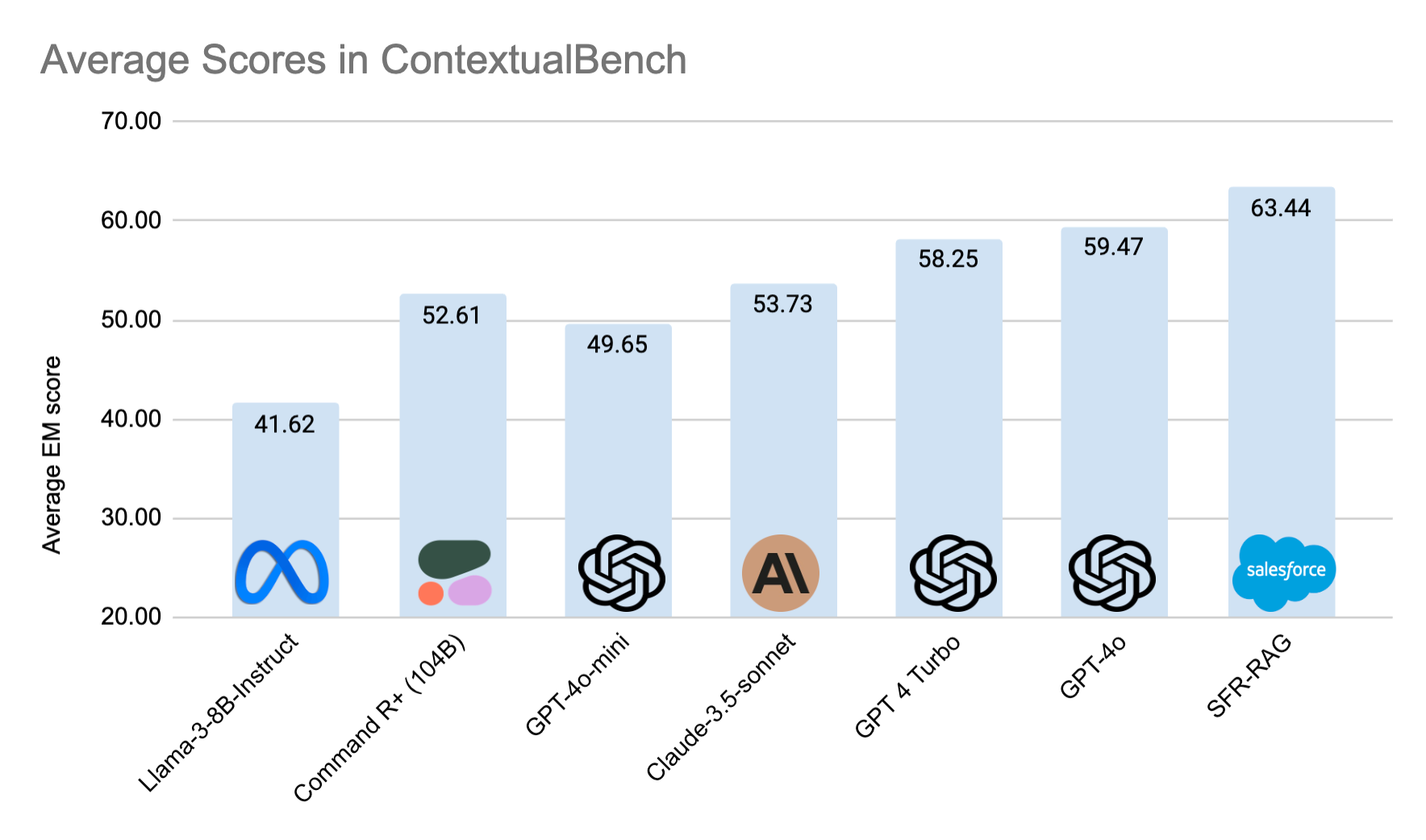
To reliably evaluate LLMs in contextual question-answering tasks that are relevant to RAG, we also release ContextualBench, an evaluation suite consisting of 7 contextual benchmarks, such as HotpotQA and 2WikiHopQA, that are measured with consistent setups.
SFR-RAG surpasses GPT-4o and achieves the state of the art in 3 out of 7 benchmarks in ContextualBench, and overwhelmingly outperforms Command-R+ with 10 times fewer parameters. SFR-RAG is also shown to largely overshadow notable baselines in respecting the context information strongly and faithfully, even when the contextual facts are fabricated, altered, removed or contradicting.
Reliable RAG Application with A New Chat Template
Most language models come with a standard chat template with 3 conversational roles: System, User, and Assistant. However, as LLMs take on more complex use cases like RAG, where the models have to perform multiple steps of reasoning and tool uses before arriving at the final answer. Common implementations usually place these non-conversational steps inside the Assistant turn. There are several disadvantages to this design:
- Security and privacy issues may arise if such internal data processing steps involve sensitive information because the steps may be shown to the users.
- Application reliability is uncertain as those reasoning steps and tool use outputs need to be parsed using keywords produced in the Assistant turn, which the model may fail to generate.
- Training LLMs for complex RAG tasks is not straightforward because we need to perform customized token masking on parts of the Assistant turn. It is also difficult to fine-tune the LLMs for safety when malicious prompts and instructions may be injected as part of the contextual content.

To solve those issues, we propose a simple modification of the chat template by introducing 2 optional roles: Thought and Observation.
- Thought is where the LLM may freely talk to itself, perform actions, or reason.
- Observation is where external contextual information is housed.
The separation of intermediate thoughts and function returned results from the Assistant turn allows us to easily fine-tune the LLM without tedious masking logic or a keyword parser. It also helps developers build RAG applications with ease as they can display or hide the thoughts and retrieved documents from the user according to their use cases, and extract contents without a cumbersome and unreliable parser. More importantly, the Assistant turn is now relieved from the extra responsibilities and may now focus on delivering user-friendly responses.
SFR-RAG Contextual Performances
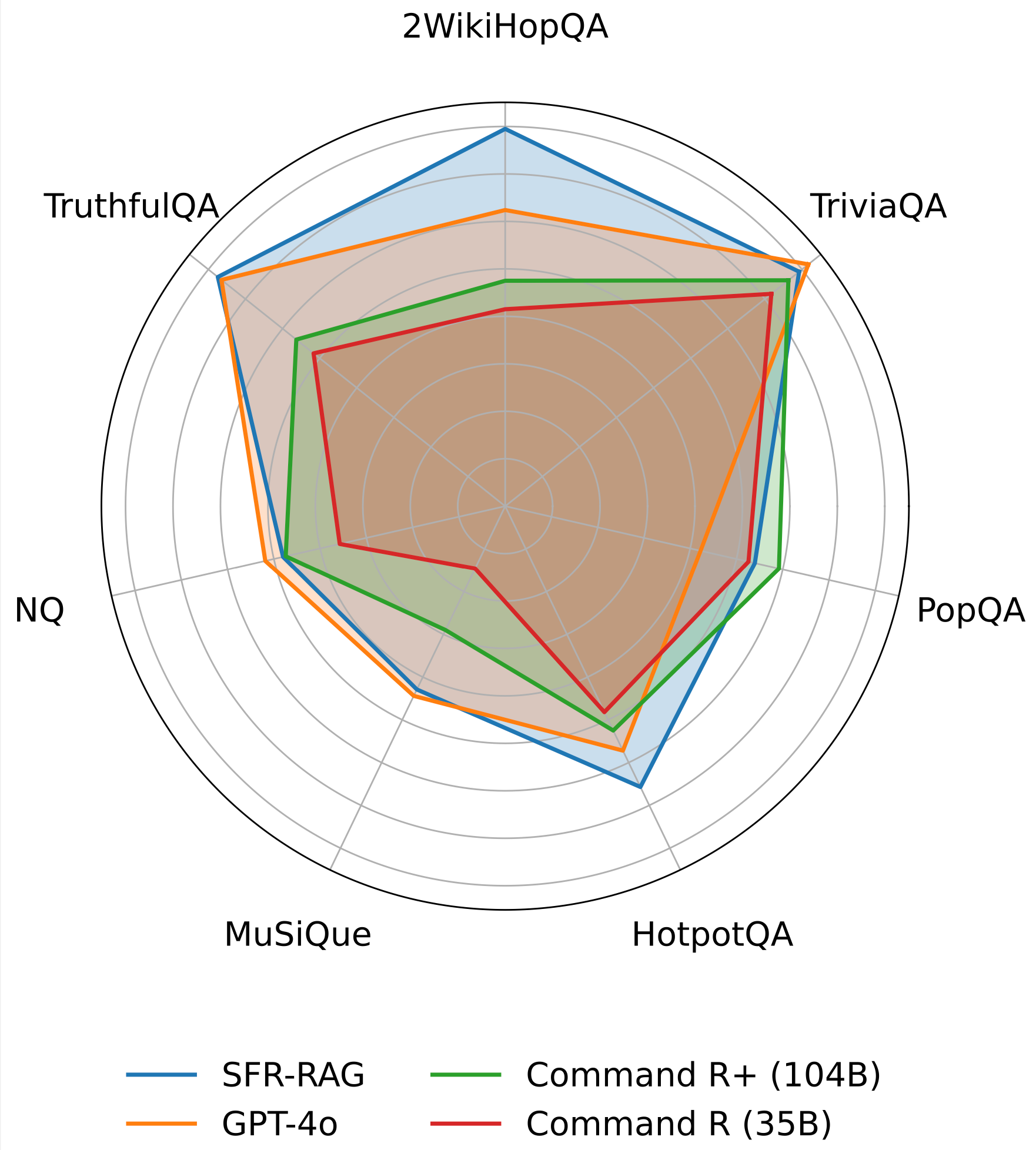
SFR-RAG achieves the state of the art in 3 out of 7 benchmarks in the ContextualBench suite, with the highest average score. SFR-RAG has the highest margin in 2WikiHopQA. It outperforms Command-R+ in almost all benchmarks, with 10 times fewer parameters.
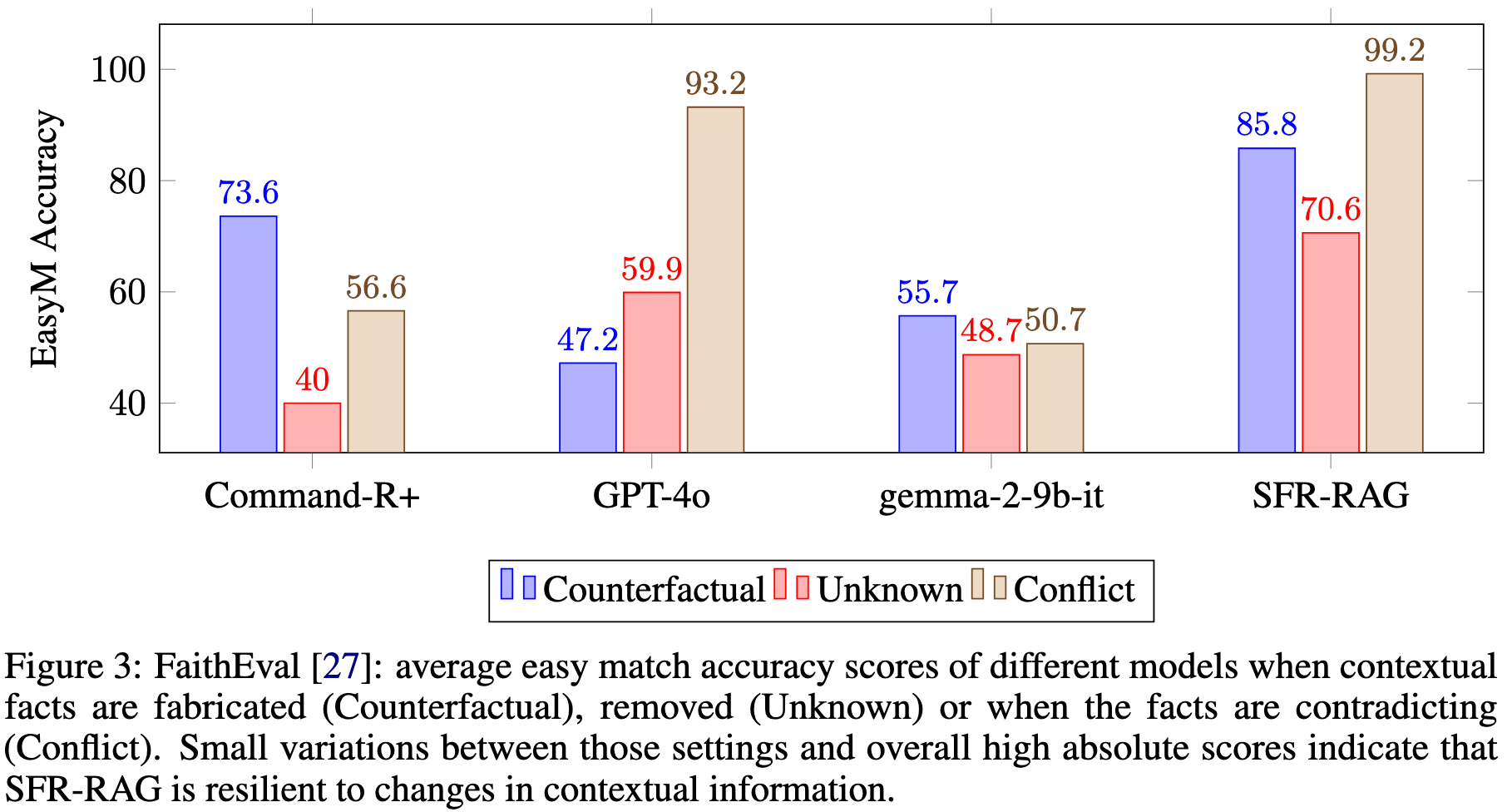
SFR-RAG is robust and resilient to novel changes to the context documents as evaluated by the FaithEval suite, which measures how faithful to the context a language model is. As shown in Figure 3, SFR-RAG achieves higher scores in all categories, namely Counterfactual, Unknown, and Conflict. This means the model is faithful to the context even if the facts are changed or become counter-intuitive (Counterfactual). The model can also recognize if the context does not contain the answer (Unknown) and it contains conflicting information (Conflict). The results indicate that SFR-RAG is less prone to hallucination than alternatives, which is the utmost important criterion for building a reliable RAG application.
SFR-RAG will be made available via API soon. Any unreleased services or features referenced here are not currently available and may not be delivered on time or at all. Customers should make their purchase decisions based upon features that are currently available.
Learn More:
Paper: https://arxiv.org/pdf/2409.09916
ContextualBench evaluation framework: https://huggingface.co/datasets/Salesforce/ContextualBench
Salesforce AI Research Github:
https://github.com/SalesforceAIResearch/SFR-RAG
ContextualBench-leaderboard: https://huggingface.co/spaces/Salesforce/ContextualBench-Leaderboard

























