


- Economic inequality is accelerating globally and is a growing concern due to its negative impact on economic opportunity, health and social welfare. Taxes are important tools for governments to reduce inequality. However, finding a tax policy that optimizes equality along with productivity is an unsolved problem. The AI Economist brings reinforcement learning (RL) to tax policy design for the first time to provide a purely simulation and data-driven solution.
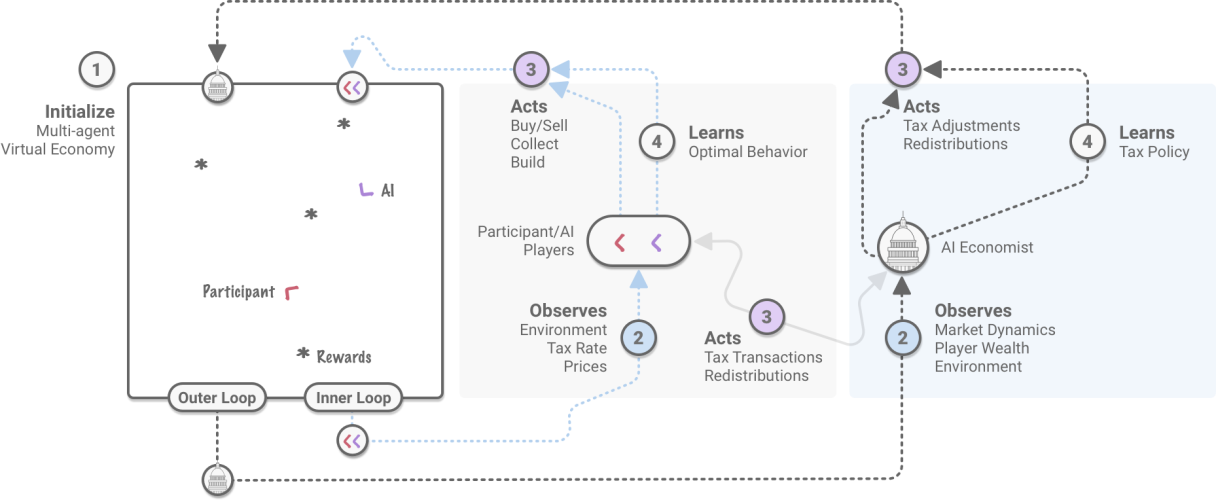
- The AI Economist uses a two-level RL framework (agents and tax policy) to learn dynamic tax policies in principled economic simulations. This framework does not use prior world knowledge or modeling assumptions, can directly optimize for any socioeconomic objective, and learns from observable data alone.
- Our experiments show the AI Economist can improve the trade-off between equality and productivity by 16%, compared to a prominent tax framework proposed by Emmanuel Saez, with even larger gains over an adaptation of the US Federal income tax and the free market.
- Without endorsing this particular schedule, it is interesting that the AI Economist implements qualitatively different tax schedules than the baselines, with higher top tax rates and lower rates for middle incomes. Furthermore, it is robust in the face of emergent tax gaming strategies.
- Moreover, the AI Economist is effective in simulations with human participants, achieving competitive equality-productivity trade-offs with the baselines and significantly higher income-weighted average social welfare. This suggests promise in using this approach to improve social outcomes in real economies.
- Our vision for the AI Economist is to enable an objective study of policy impact on real-world economies, at a level of complexity that traditional economic research cannot easily address. We believe the intersection of machine learning and economics presents a wide range of exciting research directions, and gives ample opportunity for machine learning to have positive social impact.
Reinforcement Learning for Social Good
Our work fits within a larger context of recent advances in RL. RL has been used to train AIs to win competitive games, such as Go, Dota, and Starcraft. In those settings, the RL objective is inherently adversarial (“beat-the-other-team”). Machine learning has also been used for the design of auction rules. In this work, we instead focus on the opportunity to use AI to promote social welfare through the design of optimal tax policies in dynamic economies.
- Mastering The Game Of Go Without Human
Knowledge. Silver, David, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja
Huang, Arthur Guez, Thomas Hubert et al. Nature 550, no. 7676 (2017): 354-359. - Grandmaster Level In Starcraft Ii
Using Multi-Agent Reinforcement Learning. Vinyals, Oriol, Igor Babuschkin, Wojciech M.
Czarnecki, Michaël Mathieu, Andrew Dudzik, Junyoung Chung, David H. Choi et al. Nature 575, no. 7782 (2019):
350-354. - Dota 2 With Large Scale Deep Reinforcement
Learning. Berner, Christopher, Greg Brockman, Brooke Chan, Vicki Cheung, Przemysław Dębiak,
Christy Dennison, David Farhi et al. arXiv preprint arXiv:1912.06680 (2019). - Optimal Auctions Through Deep
Learning. Dütting, Paul, Zhe Feng, Harikrishna Narasimhan, David C. Parkes, and Sai
Srivatsa Ravindranath. In International Conference on Machine Learning, pp. 1706-1715 (2019).
The Challenge of Optimal Tax Design
Many studies have shown that high income inequality can negatively impact economic growth and economic opportunity. Taxes can help reduce inequality, but it is hard to find the optimal tax policy. Economic theory cannot fully model the complexities of the real world. Instead, tax theory relies on simplifying assumptions that are hard to validate, for example, about the effect of taxes on how much people work. Moreover, real-world experimentation with taxes is almost impossible.
- Inequality Matters. United Nations.
- Literature Review On Income Inequality And The Effects On Social
Outcomes. Beatrice d’Hombres, Anke Weber, and Leandro Elia. JRC Scientific and Policy
Reports, 2012 - Income Inequality and Health: What Have
We Learned So Far? S. V. Subramanian, Ichiro Kawachi. Epidemiologic Reviews, Volume 26,
Issue 1, July 2004, Pages 78–91 - Rising Inequality Affecting More
Than Two-Thirds Of The Globe, But It’s Not Inevitable: New UN Report. UN News. - Global Inequality.
Inequality.org. - World
Inequality Report. 2018
The Economic Model of Income, Labor, Skill, and Utility
Classic tax theory focuses on people who earn income by performing labor. A worker gains utility from income but incurs the cost of labor effort. At some point, the extra utility from additional income does not outweigh the cost of additional effort.
For instance, working on weekends might earn you more money, but the effort might not be worth it to you.
A key assumption is that people differ in their skill level. Low-skilled workers receive a lower hourly wage, and so earn less money than high-skilled workers for the same amount of labor. This leads to inequality.
The Central Tax Dilemma
As a policy goal, a government may prefer to tax and redistribute income in order to improve equality. However, higher taxation can discourage work and may particularly affect high-skilled workers. An optimal tax policy optimizes this balance between equality and productivity.

A prominent tax framework, proposed by Emmanuel Saez, derives a simple optimal tax formula. However, this formula requires knowing how labor responds to changes in tax rates (“elasticity”) and makes strong assumptions, for example, that the economy is static and workers do not gain new skills. Other work has studied dynamic economic systems, but needs simplifying assumptions in order to attain analytical solutions. For an extended overview of related work, see our technical paper.
- Using Elasticities To Derive Optimal
Income Tax Rates. Saez, Emmanuel
The Review Of Economic Studies 68.1 (2001): 205-229. - The New Dynamic Public Finance. Kocherlakota, Narayana R.
Princeton; Oxford: Princeton University Press, 2010.
Economic Simulation as a Learning Environment
The AI Economist is a purely simulation and data-driven approach to the design of optimal tax policies. It uses a principled economic simulation with both workers and a policy maker (a “planner” in the economics literature), all of whom are collectively learning using reinforcement learning.

Gathering, Trading and Building
The simulation uses a two-dimensional world. There are two types of resources: wood and stone. Resources are scarce: they appear in the world at a limited rate. Workers move around, gather and trade resources, and earn income by building houses (this costs stone and wood). Houses block access: workers cannot move through the houses built by others. The simulation runs this economy over the course of an episode, which is analogous to a “working career.”
Skill and Utility
A key feature is that workers have different skills. Higher-skilled workers earn more income for building houses, and thus more utility. Building houses also takes effort, which lowers utility. Workers also pay income taxes and the collected tax is redistributed evenly among the workers. Together, these economic factors and the various competitive drivers mean that workers need to be strategic in order to maximize their utility.
Emergent Specialization
Our economic simulation produces rich behavior when AI agents (the agents are the workers in the economy) learn to maximize their utility. A salient feature is specialization: AI agents with lower skill become gatherer-and-sellers and earn income by collecting and selling stone and wood. Agents with higher skill specialize as buyer-and-builders and purchase stone and wood in order to more quickly build houses.

We do not impose such roles or behaviors directly. Rather, specialization emerges because differently skilled workers learn to balance their income and effort. This demonstrates the richness of the economic simulation and builds trust that agents respond to economic drivers. Complex emergent economic behavior has been previously studied in economics through agent-based modeling, but this has largely proceeded without the benefit of recent advances in AI.
- Agent-Based Modeling: Methods And
Techniques For Simulating Human Systems. Bonabeau, Eric.
Proceedings Of The National Academy Of Sciences 99, no. suppl 3 (2002): 7280-7287. - An Agent Based Model For Studying
Optimal Tax Collection Policy Using Experimental Data: The Cases Of Chile And Italy.
Garrido, Nicolás and Mittone, Luigi.
The Journal of Socio-Economics 42 (2013): 24-30.
Optimal Tax Design as Learned Reward Design Using Reinforcement Learning
Reinforcement learning is a powerful framework in which agents learn from experience collected through trial-and-error. We use model-free RL, in which agents do not use any prior world knowledge or modeling assumptions. Another benefit of RL is that agents can optimize for any objective.
In our setting, this means that a tax policy can be learned that optimizes any social objective, and without knowledge of workers’ utility functions or skills.

Finding optimal taxes when both workers and the policy maker are learning poses a challenging two-level RL problem:
- In the inner loop, self-interested workers perform labor, receive income, and pay taxes. They learn through trial-and-error how to adapt their behavior to maximize utility. Given a fixed tax policy, this is a standard multi-agent reinforcement learning problem with a fixed reward function.
- In the outer loop, tax policies are adapted in order to optimize the social objective. This creates a non-stationary learning environment in which the RL agents need to constantly adapt to a changing utility landscape.
- In other words: because the post-tax income for the same type and amount of labor can change over time, agent decisions that were optimal in the past, might not be optimal in the present.
This two-level learning problem poses a technical challenge, as the simultaneous behavioral changes of agents and changes to the tax policy can lead to unstable learning behavior. We have found that a combination of techniques, including the use of learning curricula and entropy regularization, enable stable convergence. These are described in our technical paper.
AI-Driven Tax Policies Improve the Trade-off between Equality and Productivity
Our reinforcement learning approach produces dynamic tax policies that yield a substantially better trade-off between equality and productivity than baseline methods.
Periodic Income Taxes
We compared the AI Economist with
- The free market with no taxation or redistribution.
- A scaled 2018 US Federal tax schedule. This is a progressive tax: marginal tax rates increase with income.
- An analytical tax formula proposed by Emmanuel Saez. In our setting, this yields a regressive tax schedule: marginal tax rates decrease with income.
All tax policies make use of seven income brackets, following the framework of the US Federal Income Tax schedule, but varying in their tax rates. The total tax is calculated by summing up the tax for each bracket in which there is income.
Episodes are divided into ten tax periods of equal length. Throughout each tax period agents interact with the environment to earn income and, at the end of the period, incomes are taxed according to the period’s tax schedule and redistributed evenly to workers. The tax policy of the AI Economist allows the tax schedule to vary across periods.
We set-up the economic environment such that the fraction of worker incomes per income bracket is in rough alignment with those in the US economy.
Improved Economic Outcomes with the AI Economist
Our experiments show that the AI Economist achieves at least a 16% gain in the trade-off between equality and productivity compared to the next best framework, which is provided by the Saez framework. The AI Economist improves equality by 47% compared to the free-market at only an 11% decrease in productivity.


Wealth Transfer and Tax Impact
Compared with the baselines, the AI Economist features a more idiosyncratic structure: a blend of progressive and regressive schedules. In particular, it sets a higher top tax rate (income above 510), a lower tax rate for incomes between 160 and 510, and both higher and lower tax rates on incomes below 160.

The collected taxes are redistributed evenly among the agents. In effect, the lower-income agents receive a net subsidy, even though their tax rates are higher (before subsidies). In other words, under the AI Economist, the lowest incomes have a lower tax burden compared to baselines.

We observed that under the Saez framework, the gatherer-and-sellers collect fewer resources than with the AI Economist. This forces the buyer-and-builders to spend more time to collect resources themselves, which lowers their productivity. At the same time, the Saez framework yields less equality through redistribution as its tax schedule is more regressive. In sum, this yields a worse balance between productivity and equality.
Robustness Against Tax Gaming Strategies
Finding optimal taxes can be challenging because AI agents can learn to “game” tax schemes. In our simulation, agents learn that they can lower their average effective tax by alternating between earning high and low incomes, rather than earning a smooth income across periods. This tax gaming occurs for the Saez tax and AI Economist due to their regressive tax rates (higher income brackets have lower tax rates). The performance of the AI Economist demonstrates that it is effective even in the face of strategic agent behavior, and the emergence of this behavior underscores the richness of the simulation-based framework.

AI-Driven Tax Policy and Real People
We also explored whether the AI Economist is effective in experiments with human participants. These experiments used a simpler ruleset to provide better usability, for instance, removing the ability to trade. However, the same economic drivers and trade-offs applied. Participants were paid real money for the utility they gained from building houses. Hence, participants were incentivized to build the number of houses that would maximize their utility. The stakes were sufficiently high: participants were paid at an average rate of at least twice the US minimum wage.
We tested all methods in a zero-shot transfer learning setting, by using the tax rates from the AI-only world in the human setting without retraining. This is an interesting evaluation, because retraining a tax policy might require a large amount of human data. The only modification was to scale down all income brackets by a factor of three to account for lower human productivity compared to AI agents. The full details are in our technical paper.

Camelback Tax Schedule Yields Strong Equality-Productivity Trade-offs
For the experiments with human participants, we selected from the set of trained AI-Driven policies a tax schedule shaped like a camelback. We compared this schedule with baselines in experiments with participants recruited on Amazon Mechanical Turk.

In 125 games with 100+ US-based participants, the camelback schedule achieved an equality-vs-productivity trade-off that is significantly better than the free market and competitive with other baselines. Participants were paid more than $20/hour on average. Compared with AI agents, people were more prone to suboptimal adversarial behaviors, such as blocking other workers. This significantly increased the variance in productivity.

Interestingly, the camelback schedule is qualitatively different from the baselines. However, the relative performance of the camelback versus the baselines is consistent across the experiments with only AI and with only people.

Significantly Higher Weighted Social Welfare
The camelback tax also statistically significantly outperformed all baselines in regard to an alternative, established social welfare metric that weights the utility of lower income workers more than higher income ones.

Future Directions
The strong zero-shot transfer performance on human play is surprising and encouraging. The camelback tax was competitive with, or outperformed, baselines, without recalibration and while being applied with different rulesets and worker behaviors. As such, these results suggest promise in the use of the AI Economist as a tool for finding good tax policies for real economies.
AI-based economic simulations still have limitations. They do not yet model human-behavioral factors and interactions between people, including social considerations, and they consider a relatively small economy. However, these kinds of simulations provide a transparent and objective view on the economic consequences of different tax policies. Moreover, this simulation and data-driven approach can be used together with any social objective in order to automatically find a tax policy with strong performance. Future simulations could improve the fidelity of economic agents using real-world data, while advances in large-scale RL and engineering could increase the scope of economic simulations.
We believe that this kind of research has great potential for increasing equality and productivity in real economies, helping to promote more just and healthy societies. We also hope that the AI Economist can foster transparency, reproducibility, and an open and facts-based discussion about applying machine learning to economic decision-making through our public research publications and open-source code. As such, our hope is that future economic AI models can robustly and transparently augment real-world economic policy-making and, in doing so, improve social welfare.
Ethical Considerations
Ethics, trust, and transparency are an integral part of Salesforce’s approach to AI research. While the current version of the AI Economist is a limited representation of the real world, and is not a tool that could be currently used with malintent to reconfigure tax policy, we recognize that it could be possible to manipulate future, large-scale iterations of the AI Economist to increase inequality and hide this action behind the results of an AI system.
Furthermore, either out of ignorance or malice, bad training data may result in biased recommendations, particularly in cases where users train the tool using their own data. For instance, the under-representation of communities and segments of the work-force in the training data could lead to bias in AI-Driven tax policies. This work also opens up the possibility of using richer, observational data to set individual taxation, an area where we anticipate a strong need for robust debate.
We encourage anyone utilizing the AI Economist to publish a model card or data sheet that describes the ethical considerations of AI-Driven tax schedules in order to increase transparency, and by extension, trust, in the system.
In order to responsibly publish this research, we have taken the following measures:
- To ensure accountability on our part, we shared the paper and an assessment of the ethical risks, mitigation strategies, and assessment of safety to publish with the following external reviewers: Dr. Simon Chesterman, Provost’s Chair and Dean of the National University of Singapore Faculty of Law, and Lofred Madzou, AI Project Lead at the World Economic Forum’s Center for the Fourth Industrial Revolution. None of the reviewers identified additional ethical concerns or mitigation strategies that should be employed. All affirmed that the research is safe to publish.
- To increase transparency, we are publishing this blog post, as well as a comprehensive technical paper, thereby allowing robust debate and broad multi-disciplinary discussion of our work.
- To further promote transparency, we will have a timed open-source release of our code for the simulation and training. This does not prevent future misuse, but we believe, at the current level of fidelity, transparency is key to promote grounded discussion and future research.
With these mitigation strategies and other considerations in place, we believe this research is safe to publish.
Additional Information
Paper: https://arxiv.org/abs/2004.13332
- The AI Economist: Improving Equality and Productivity with AI-Driven Tax Policies, Stephan Zheng, Alexander Trott, Sunil Srinivasa, Nikhil Naik, Melvin Gruesbeck, David C. Parkes, Richard Socher.
Acknowledgements
This work was a joint effort with contributions from:
Stephan Zheng, Alex Trott, Sunil Srinivasa, Nikhil Naik, Melvin Gruesbeck, Kathy Baxter, David Parkes, and Richard Socher.
We thank Lofred Madzou, Simon Chesterman, Rob Reich, Mia de Kuijper, Scott Kominers, Gabriel Kriendler, Stefanie Stantcheva, and Thomas Piketty for valuable discussions.
We also thank the following people for their valuable support:
- Video animation: Leo Ogawa Lillrank, Ivy Lillrank.
- Marketing: Katherine Siu.
- Public Relations: Kate Wesson, Steve Mnich.
References
- Inequality Matters. United Nations.
-
Literature Review On Income Inequality And The Effects On Social Outcomes. Beatrice d’Hombres,
Anke Weber, and Leandro Elia. JRC Scientific and Policy Reports, 2012. -
Income Inequality And Health: What
Have We Learned So Far? S. V. Subramanian, Ichiro Kawachi.
Epidemiologic Reviews, Volume 26, Issue 1, July 2004, Pages 78–91. -
Rising Inequality Affecting
More Than Two-Thirds Of The Globe, But It’s Not Inevitable: New Un Report. UN News. -
Global
Inequality. Inequality.org. -
World
Inequality Report. 2018. -
Using Elasticities To Derive Optimal Income Tax Rates. Saez, Emmanuel. The Review Of Economic
Studies 68.1 (2001): 205-229. -
Mastering The Game Of Go Without Human
Knowledge. Silver, David, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja
Huang, Arthur Guez, Thomas Hubert et al. Nature 550, no. 7676 (2017): 354-359. - Grandmaster Level In Starcraft Ii
Using Multi-Agent Reinforcement Learning. Vinyals, Oriol, Igor Babuschkin, Wojciech M.
Czarnecki, Michaël Mathieu, Andrew Dudzik, Junyoung Chung, David H. Choi et al. Nature 575, no. 7782 (2019):
350-354. -
Dota 2 With Large Scale Deep
Reinforcement Learning. Berner, Christopher, Greg Brockman, Brooke Chan, Vicki Cheung,
Przemysław Dębiak, Christy Dennison, David Farhi et al. arXiv preprint arXiv:1912.06680 (2019). -
Optimal Auctions Through Deep Learning. Dütting, Paul, Zhe Feng, Harikrishna Narasimhan,
David C. Parkes, and Sai Srivatsa Ravindranath. In International Conference on Machine Learning, pp. 1706-1715
(2019). -
An Agent Based Model For
Studying Optimal Tax Collection Policy Using Experimental Data: The Cases Of Chile And
Italy. Garrido, Nicolás and Mittone, Luigi. The Journal of Socio-Economics 42 (2013):
24-30. -
Agent-Based Modeling: Methods And
Techniques For Simulating Human Systems. Bonabeau, Eric. Proceedings of the national
academy of sciences 99, no. suppl 3 (2002): 7280-7287.
























