




TL;DR: We propose Moirai-MoE, the first mixture-of-experts time series foundation model, achieving token-level model specialization in a data-driven manner. Extensive experiments on 39 datasets reveal that Moirai-MoE delivers up to 17% performance improvements over Moirai at the same level of model size and outperforms other time series foundation models, such as Chronos (from Amazon) and TimesFM (from Google) with up to 65 times fewer activated parameters.
The emergence of universal forecasters
Time series forecasting is undergoing a transformative shift. The traditional approach of developing separate models for each dataset is being replaced by the concept of universal forecasting, where a pre-trained foundation model can be applied across diverse downstream tasks in a zero-shot manner, regardless of variations in domain, frequency, dimensionality, context, or prediction length. This new paradigm significantly reduces the complexity of building numerous specialized models, paving the way for forecasting-as-a-service.
For instance, cloud computing service providers can leverage a single model to fulfill forecasting needs across various downstream tasks. This capability is especially vital given the dynamic demand for computing resources and the expanding size of IT infrastructure.
Challenges and our new approach: Sparse Mixture-of-Experts Transformers for Time Series
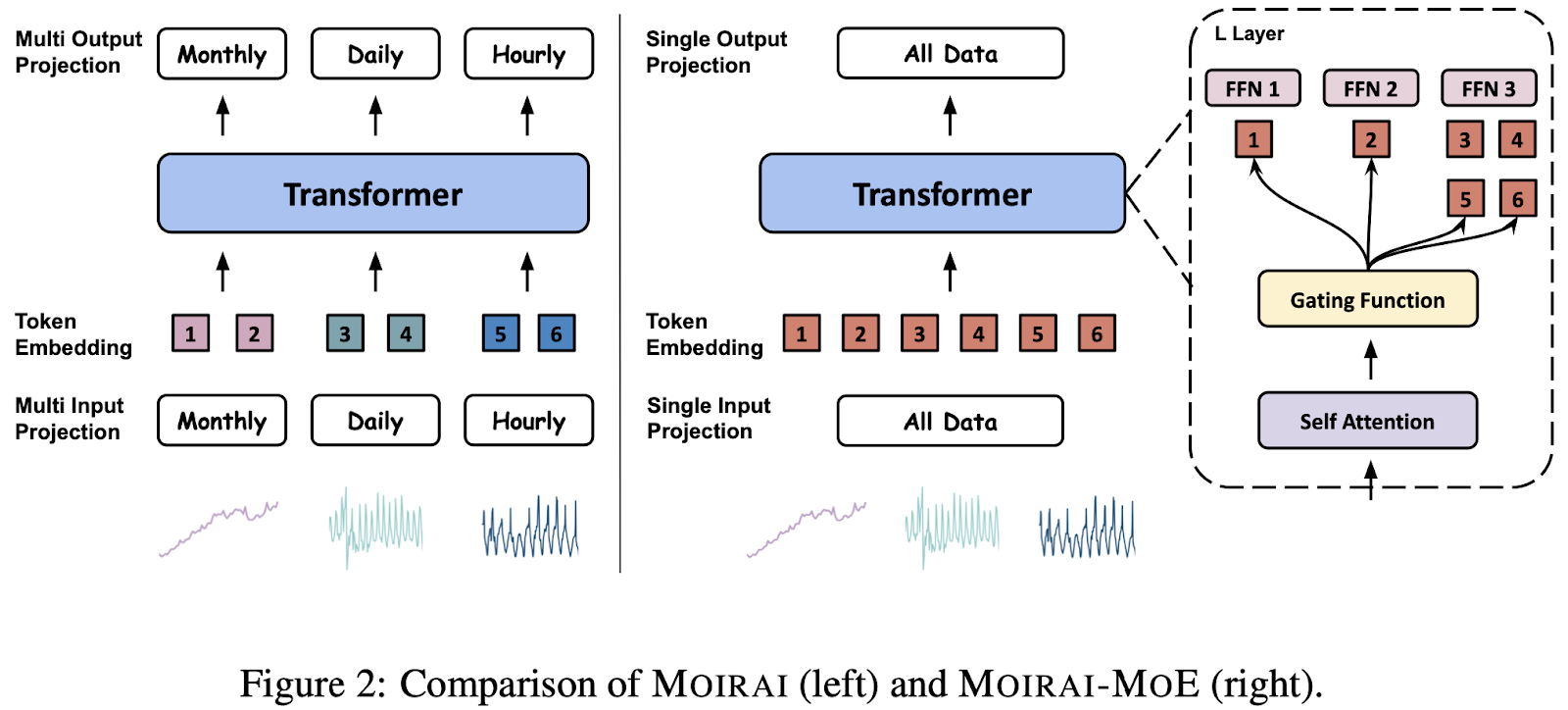
To excel in zero-shot forecasting, time series foundation models are pre-trained on massive data from a variety of sources. However, time series data is inherently heterogeneous, posing significant challenges for unified time series training. Existing approaches introduce some level of model specialization to account for the highly heterogeneous nature of time series data. For instance, Moirai employs multiple input/output projection layers, each tailored to handle time series at a specific frequency.
In this study, we introduce our new approach Moirai-MoE, which automates this model specialization process by utilizing the techniques of sparse mixture-of-experts Transformers to capture diverse time series patterns. Figure 2 presents a comparison between Moirai and Moirai-MoE. We can see that compared to Moirai using multi-heuristic-defined input/output projection layers to model time series with different frequencies, Moirai-MoE utilizes a single input/output projection layer while delegating the task of capturing diverse time series patterns to the sparse mixture of experts Transformers. With these designs, the specialization of Moirai-MoE is achieved in a data-driven manner and operates at the token level.
In addition, Moirai-MoE adopts a decoder-only training objective to improve training efficiency by enabling parallel learning of various context lengths in a single model update.
Results
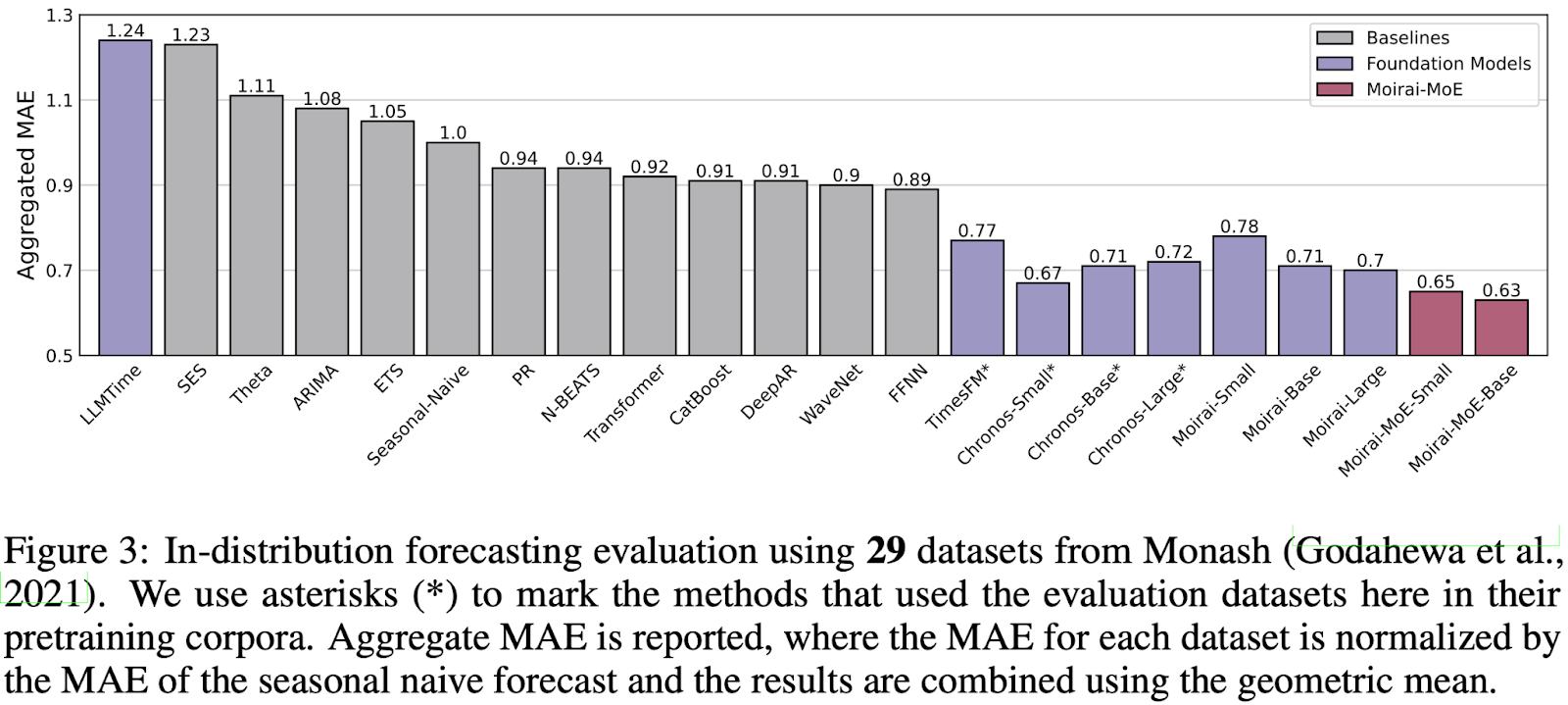
We begin with an in-distribution evaluation using a total of 29 datasets from the Monash benchmark (see Figure 3). The evaluation results show that Moirai-MoE beats all competitors. In particular, Moirai-MoE-Small drastically surpasses its dense counterpart Moirai-Small by 17%, and also outperforms the larger models Moirai-Base and Moirai-Large by 8% and 7%, respectively.
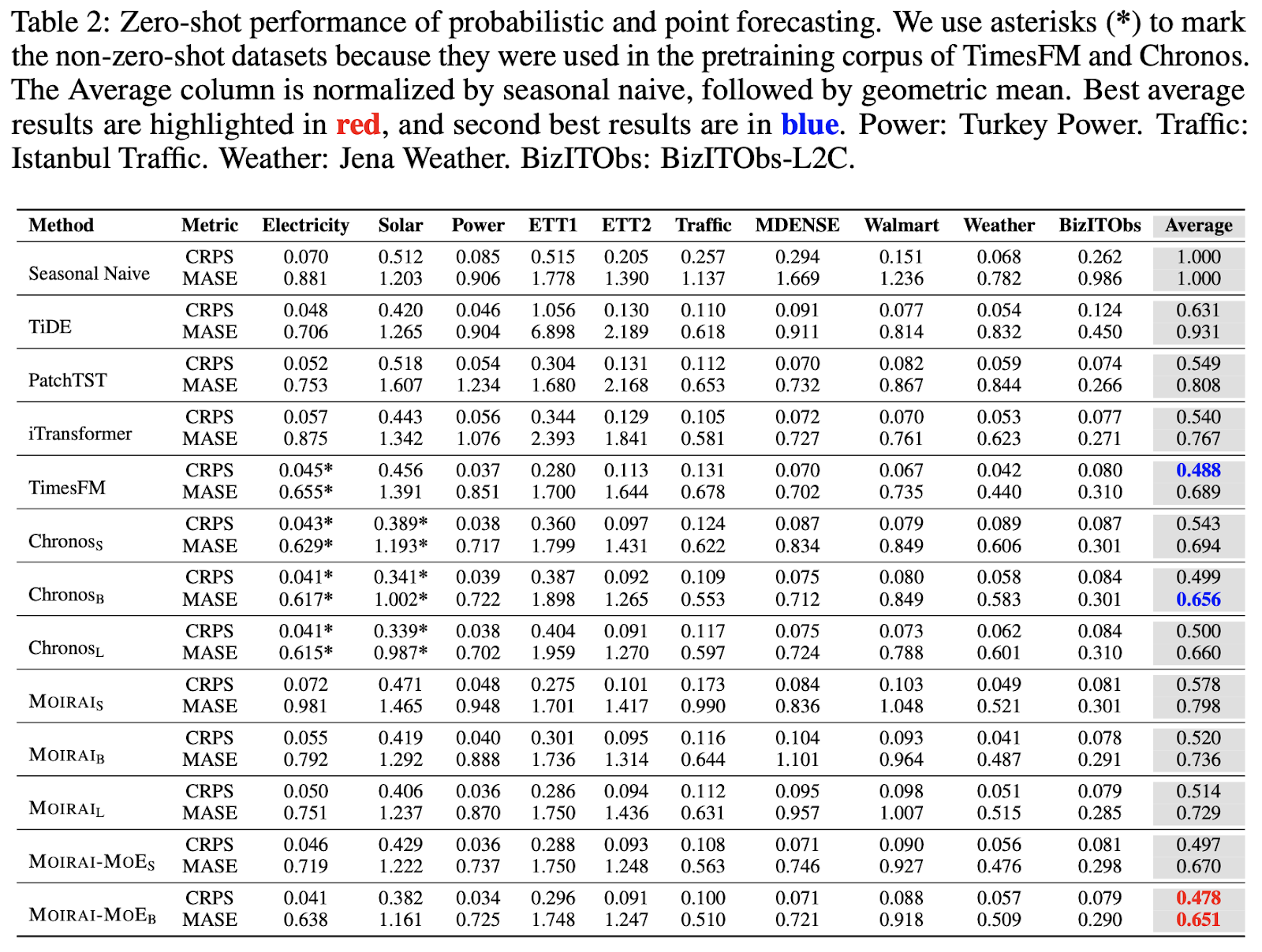
We conduct a zero-shot forecasting evaluation on 10 datasets. To establish a comprehensive comparison, we report results for both probabilistic and point forecasting, using continuous ranked probability score (CRPS) and mean absolute scaled error (MASE) as evaluation metrics. The results are presented in Table 2. Moirai-MoE-Base achieves the best zero-shot performance, even outperforming TimesFM and Chronos, which include partial evaluation data in their pretraining corpora. When compared to all sizes of Moirai, Moirai-MoE-Small delivers a 3%–14% improvement in CRPS and an 8%–16% improvement in MASE. These improvements are remarkable, considering that Moirai-MoE-Small has only 11M activated parameters — 28 times fewer than Moirai-Large.
Explore more
Salesforce AI Research invites you to dive deeper into the concepts discussed in this blog post. Connect with us on social media and our website to get regular updates on this and other research projects.
- Check out our Research Paper, which describes our work in greater detail.
- Check out our code on GitHub
- Follow us on Twitter: @SFResearch, @Salesforce
- Read our other AI Research Blogs
- To learn more about all of the exciting projects at Salesforce AI Research, please visit us at https://www.salesforceairesearch.com



























