Em tempos de transformação digital, em que as empresas investem cada vez mais em marketing digital e estratégias baseadas na captura de informações virtuais, a criação de um banco de dados é inevitável. Na verdade, tudo o que gira em torno de acervos de informações está relacionado a bancos de dados – por isso, podemos dizer que eles sempre existiram, independente da popularização da internet.
Nesse sentido, podemos dizer que um banco de dados é uma coleção organizada de informações estruturadas, normalmente armazenadas eletronicamente em um sistema de computador. Dessa forma, é um banco de dados geralmente controlado por um sistema de gerenciamento de banco de dados (DBMS).
Juntos, os dados e o DBMS, somados aos aplicativos associados a eles, são chamados de sistema de banco de dados, geralmente abreviados para apenas banco de dados. Os dados nos tipos mais comuns de bancos de dados em operação atualmente são modelados em linhas e colunas em uma série de tabelas para tornar o processamento e a consulta de dados eficientes.
Os dados podem ser facilmente acessados, gerenciados, modificados, atualizados, controlados e organizados. A maioria dos bancos de dados usa a linguagem de consulta estruturada (SQL) para escrever e consultar dados.
O que teremos pela frente?
Relatório State of Data Analytics
Entrevistamos mais de 10 mil líderes, analistas e executivos de TI sobre o gerenciamento de dados e a tomada de decisões na era da IA. Conheça todos os insights!



LEIA MAIS: O que é o Zero Copy? (e como funciona)
O que é um banco de dados?
O banco de dados é como uma coletânea de dados, onde é possível recolher, armazenar e promover o acesso facilitado às informações de consulta dos dados. Assim, o conceito de um banco de dados é uma espécie de servidor físico que permite registrar inúmeras informações simultâneas sobre qualquer coisa.
Portanto, o banco de dados é essencial para o crescimento de uma empresa, por meio dele que é possível manter um histórico atualizado sobre as transações que foram realizadas, além de possibilitar a análise dos dados para a criação de insights e estratégias voltadas para o desenvolvimento da empresa e com uma abordagem customer centric.
Além disso, como comentamos anteriormente, a maioria dos bancos de dados usa a SQL para escrever e consultar dados. A SQL é uma linguagem de programação usada para manipular e definir dados e fornecer controle de acesso.
Banco de dados X Planilhas: qual a diferença?
Até a popularização dos bancos de dados, as planilhas atuavam como repositores e organizadores de informações são modos convenientes de armazenar informações. Contudo, com a modernização das ferramentas operacionais, as planilhas estão caindo em desuso. Nesse sentido, as principais diferenças entre os dois são:
- Como os dados são armazenados e manipulados
- Quem pode acessar os dados
- Quantos dados podem ser armazenados
As planilhas foram originalmente projetadas para um usuário e suas características refletem isso. São ótimos para um único usuário ou um pequeno número de usuários que não precisam fazer uma manipulação de dados muito complicada.
Por outro lado, bancos de dados são projetados para conter coleções muito maiores de informações organizadas. Dessa maneira, os bancos de dados permitem que vários usuários, ao mesmo tempo, acessem e consultem com rapidez e segurança os dados usando lógica e linguagem altamente complexas.
LEIA MAIS: Indicadores de desempenho: o que são e como acompanhar?
Quais são os principais tipos de bancos de dados?
Existem muitos tipos diferentes de bancos de dados. Porém, o melhor banco de dados para uma organização específica depende de como a organização pretende usar os dados.
Dois dos principais tipos de bancos de dados são os relacionais (SQL) ou não relacionais (NoSQL). Neste sentido, a principal diferença está nos métodos de armazenamento de dados para aplicações.
O banco de dados relacional (SQL) armazena dados em formato tabular com linhas e colunas. As colunas contêm atributos de dados, e as linhas têm valores de dados. Assim é possível vincular as tabelas em um banco de dados relacional para obter insights mais profundos sobre a interconexão entre diversos pontos de dados.
Por sua vez, bancos de dados não relacionais (NoSQL) usam uma variedade de modelos de dados para acessar e gerenciar dados. Eles são otimizados especificamente para aplicações que exigem grande volume de dados, baixa latência e modelos de dados flexíveis, o que é obtido relaxando algumas das restrições de consistência de dados de outros bancos de dados.
Como os bancos de dados relacionais armazenam dados?
Como mencionamos, os bancos de dados relacionais armazenam dados em tabelas com colunas e linhas. Mas o que isso significa? Significa que cada coluna representa um atributo de dados específico, e cada linha representa uma instância desses dados.
Desse modo, cada tabela recebe uma chave primária: uma coluna identificadora que identifica a tabela de maneira exclusiva. Essa chave primária é usada para estabelecer relações entre tabelas.
Você a usa para relacionar linhas entre tabelas como a chave externa em outra tabela. Quando duas tabelas estão conectadas, você obtém dados de ambas com uma única consulta. Você pode escrever consultas SQL para interagir com o banco de dados relacional. É graças à lógica do banco de dados relacional que se popularizou o uso de planilhas eletrônicas para controle de informações.
Para exemplificar, imagine que um varejista de eletrônicos crie uma tabela com todos os seus produtos. Nessa tabela, você pode ter colunas para os nomes, as descrições e os preços dos produtos. Outra tabela contém dados sobre clientes, seus nomes e o que eles compraram.
Assim, as tabelas teriam o seguinte formato:
- Tabela de produtos
| Product_id (Chave primária) | Product_name | Product_cost |
| P1 | Product_A | 100_USD |
| P2 | Product_B | 250_USD |
| P3 | Product_C | 350_USD |
- Tabela de clientes
| Customer_id | Customer_name | Item_purchased (Chave externa) |
| C1 | Customer_Amanda | P2 |
| C2 | Customer_Bela | P3 |
| C3 | Customer_Carlos | P1 |
Apesar do exemplo dado se referir a um varejista de eletrônicos, um banco de dados relacional pode ser considerado para qualquer necessidade de informações na qual os pontos de dados se relacionam entre si.
LEIA MAIS: Conheça o MINT-1T, Um Conjunto de dados Multimodal com Um Trilhão de Tokens
Como bancos de dados não relacionais armazenam dados?
Primeiro, é preciso reforçar que existem vários sistemas de banco de dados não relacionais diferentes. Isso ocorre devido às variações na forma como gerenciam e armazenam dados sem esquema – dados armazenados sem as restrições exigidas pelos bancos de dados relacionais.
Dessa forma, a principal diferença entre bancos de dados relacionais e não relacionais é que este último não usa tabelas com colunas e linhas como estrutura organizadora de informações.
Em vez disso, eles usam um modelo de armazenamento otimizado para os requisitos específicos do tipo de dados que está sendo armazenado. Os bancos de dados não relacionais permitem que conjuntos maiores de dados distribuídos sejam acessados, atualizados e analisados rapidamente..
Já o termo NoSQL refere-se aos armazenamentos de dados que não usam o SQL ou não apenas o SQL para consultas. Ao contrário, os bancos de dados NoSQL usam outras linguagens de programação e outros construtos para consultar os dados.
Muitos bancos de dados NoSQL dão suporte a consultas compatíveis com SQL, mas a maneira como eles executam essas consultas é geralmente diferente de como um banco de dados relacional tradicional executa a mesma consulta SQL.
Um tipo de banco de dados não relacional, um banco de dados de objeto, usa a programação orientada a objeto. Os objetos são codificados com um estado (dados reais) que é armazenado em um campo ou uma variável e um comportamento exibido por meio de um método ou uma função.
Os objetos podem ser mantidos no armazenamento persistente para sempre e lidos e mapeados diretamente sem uma API nem uma ferramenta, o que produz acesso mais rápido aos dados e melhor desempenho. No entanto, os bancos de dados de objetos não são tão populares quanto outros tipos de bancos de dados e podem ser difíceis de dar suporte.
Ao contrário dos bancos de dados relacionais, que precisam de dados padronizados, os bancos de dados não relacionais são mais flexíveis e úteis para dados com requisitos variáveis. Você pode usá-los, por exemplo, para armazenar imagens, vídeos, documentos e outros conteúdos semiestruturados e não estruturados.
Na tabela, você pode conferir um resumo sobre as principais diferenças entre bancos de dados SQL e NoSQL:
| Relacional ou SQL | Document ou NoSQL |
| Organizados como um conjunto de tabelas com colunas e linhas (rows) | Permite que dados não estruturados e semiestruturados sejam armazenados e manipulados |
| Esquema rígido | Esquema livre |
| Altamente normalizado | Tipicamente denormalizado |
| Dominante desde 1980 | Populares à medida que os aplicativos web se tornaram mais comuns e mais complexos. |
Apesar de esses dois tipos de bancos de dados serem os mais conhecidos, existem também outras estruturas de armazenamento, como você pode conferir a seguir:
- Bancos de dados orientados a objetos: as informações são representadas na forma de objetos, como na programação orientada a objetos.
- Bancos de dados distribuídos: dois ou mais arquivos localizados em sites diferentes. O banco de dados pode ser armazenado em vários computadores, localizados no mesmo local físico ou espalhados por diferentes redes.
- Data warehouses: um repositório central de dados, um data warehouse é um tipo de banco de dados projetado especificamente para consultas e análises rápidas.
- Bancos de dados OLTP: um banco de dados rápido e analítico projetado para um grande número de transações realizadas por vários usuários.
Outros bancos de dados menos comuns são adaptados para funções científicas, financeiras ou outras muito específicas. Além dos diferentes tipos de banco de dados, as mudanças nas abordagens de desenvolvimento de tecnologia e os avanços dramáticos, como a nuvem e a automação, estão impulsionando os bancos de dados em direções totalmente novas.
Para finalizar, existem ainda bancos de dados hospedados na nuvem, os quais são compostos por uma coleção de dados, estruturados ou não estruturados, que residem em uma plataforma de computação em nuvem privada, pública ou híbrida. Além disso, existem dois tipos de modelos de banco de dados em nuvem: tradicional e banco de dados como serviço (DBaaS). Com o DBaaS, as tarefas administrativas e a manutenção são executadas por um provedor de serviços.
LEIA MAIS: First-Party Data: como você pode ter sucesso em um mundo sem cookies
Para que serve um banco de dados?
Bancos de dados servem para armazenar todas as informações contidas nos seus sites, e-commerce, pontos de contato com o cliente e muito mais. Através da coleta e categorização desses dados, você tem a possibilidade de gerar informação relevante, e, assim, criar estratégias mais personalizadas para se comunicar com cada um dos seus clientes.
Vale dizer que esses dados corretamente organizados irão ajudar a melhorar não só a experiência desses visitantes, como também a rotina da sua área de TI. Afinal, seus profissionais conseguirão acessar, armazenar e restaurar os dados sempre que necessário com o uso de uma boa ferramenta de gestão de banco de dados.
Como estruturar um banco de dados corretamente?
A dúvida que pode surgir para você agora é: como começar a estruturar um banco de dados do qual você possa extrair valor? Bem, você tem dois caminhos para isso: utilizar planilhas e gastar muito tempo e força operacional – ou você pode apostar no Data Cloud para coletar e organizar os dados que interessam ao seu negócio.
A seguir, vamos entrar em um passo a passo detalhado para você entender como se estrutura um banco de dados. Confira!
1 – Análise de requisitos: identificando o objetivo do banco de dados
Compreender a finalidade do banco de dados servirá de base para informar suas escolhas durante todo o processo de criação. Certifique-se de considerar o banco de dados de todas as perspectivas.
Por exemplo, se você estiver criando um banco de dados para o setor de marketing utilizar nas suas estratégias de CRM, seria importante considerar as maneiras pelas quais os profissionais de marketing (usuários) precisam acessar os dados.
Aqui estão algumas maneiras de coletar informações antes de criar o banco de dados:
- Entreviste as pessoas que o usarão;
- Analise formulários corporativos, como faturas, quadros de horários e pesquisas;
- Faça um pente fino em todos os sistemas de dados existentes (incluindo arquivos físicos e digitais);
- Comece reunindo todos os dados existentes que serão incluídos no banco de dados;
- Em seguida, liste os tipos de dados que você deseja armazenar e as entidades, ou pessoas, coisas, locais e eventos que esses dados descrevem, assim:
Clientes
| Base 1 | Base 2 | Base 3 |
| Nome | Nome | ID do pedido |
| Endereço | Preço | Representante de vendas |
| Cidade, Estado, CEP | Quantidade em estoque | Data |
| Endereço de e-mail | Quantidade em pedidos | Produto(s) |
| Produtos | Pedidos | Quantidade |
| Preço | ||
| Total |
Essas informações mais tarde se tornarão parte do dicionário de dados, que descreve as tabelas e os campos dentro do banco de dados. Certifique-se de dividir as informações em pequenas partes úteis.
Por exemplo, considere separar o endereço do país para que você possa filtrar mais tarde as pessoas pelo país de residência. Além disso, evite colocar o mesmo ponto de dados em mais de uma tabela, o que acrescenta complexidade desnecessária.
Depois de saber quais os tipos de dados que o banco de dados incluirá, de onde esses dados vêm e como eles serão usados, você estará pronto para começar a planejar o banco de dados real.
2- Estrutura de banco de dados para construir uma apresentação visual de informações
O próximo passo é estabelecer uma representação visual do seu banco de dados. Neste caso, optamos por demonstrar essa padronização tendo em vista um banco de dados relacional.
Tenha em mente a estrutura de um banco SQL tabelado, conforme mostramos acima.
Para converter suas listas de dados em tabelas, comece criando uma tabela para cada tipo de entidade, como produtos, vendas, clientes e pedidos.
Lembre-se que cada linha de uma tabela é chamada de registro. Os registros incluem dados sobre algo ou alguém, como um cliente em particular. Como comparação, as colunas (também conhecidas como campos ou atributos) contêm um único tipo de informação que aparece em cada registro, como os endereços de todos os clientes listados na tabela. Conforme exemplo abaixo:
| 1º nome | Sobrenome | Idade | Código postal |
|---|---|---|---|
| Lana | Silva | 43 | 34760 |
| Lucas | Lopes | 32 | 97453 |
| Helena | Martinez | 56 | 64829 |
Para manter os dados consistentes de um registro para o outro, atribua o tipo de dados apropriado a cada coluna. Os tipos de dados comuns incluem:
- CHAR – um tamanho específico de texto
- VARCHAR – texto de tamanhos variáveis
- TEXT – grandes quantidades de texto
- INT – número inteiro positivo ou negativo
- FLOAT, DOUBLE – também podem armazenar números de pontos flutuantes
- BLOB – dados binários
Alguns sistemas de gestão de banco de dados também oferecem o tipo de dados Autonumeração, que gera automaticamente um número exclusivo em cada linha.
Para criar uma visão geral do banco de dados, conhecido como um diagrama entidade-relacionamento, você não incluirá as tabelas reais. Em vez disso, cada tabela se torna uma caixa no diagrama. O título de cada caixa deve indicar o que os dados nessa tabela descrevem, enquanto os atributos são listados abaixo, assim:

Finalmente, você deve decidir qual atributo ou quais atributos servirão como chave primária para cada tabela, se houver. Uma chave primária (PK) é um identificador exclusivo para uma determinada entidade, o que significa que você poderia escolher um cliente exato, mesmo se você só conhecesse o valor.
Os atributos escolhidos como chaves primárias devem ser únicos, imutáveis e sempre presentes (nunca NULOS ou vazios). Por esta razão, os números de pedido e nomes de usuários são boas chaves primárias, ao contrário de números de telefone ou endereços. Você também pode usar vários campos em conjunto como chave primária (isso é conhecido como uma chave composta).
Quando se trata de criar o banco de dados real, você colocará a estrutura de dados lógicos e a estrutura de dados físicos na linguagem de definição de dados suportada pelo seu sistema de gestão de banco de dados. Nesse ponto, você também deve estimar o tamanho do banco de dados para ter certeza de que você pode obter o nível de desempenho e espaço de armazenamento que serão necessários.
3 – Criando relações entre entidades
Com suas tabelas de banco de dados agora convertidas em tabelas, você está pronto para analisar as relações entre essas tabelas. A cardinalidade se refere à quantidade de elementos que interagem entre duas tabelas relacionadas. Identificar a cardinalidade ajuda a garantir que você tenha dividido os dados em tabelas de forma mais eficiente.
Cada entidade pode potencialmente ter uma relação com todas as outras, mas essas relações normalmente são uma de três tipos:
Relações uma a uma
Quando há apenas uma instância da Entidade A para cada instância da Entidade B, diz-se que elas têm uma relação uma para uma (frequentemente escrito 1:1). Você pode indicar esse tipo de relação em um diagrama ER com uma linha com um traço em cada extremidade:
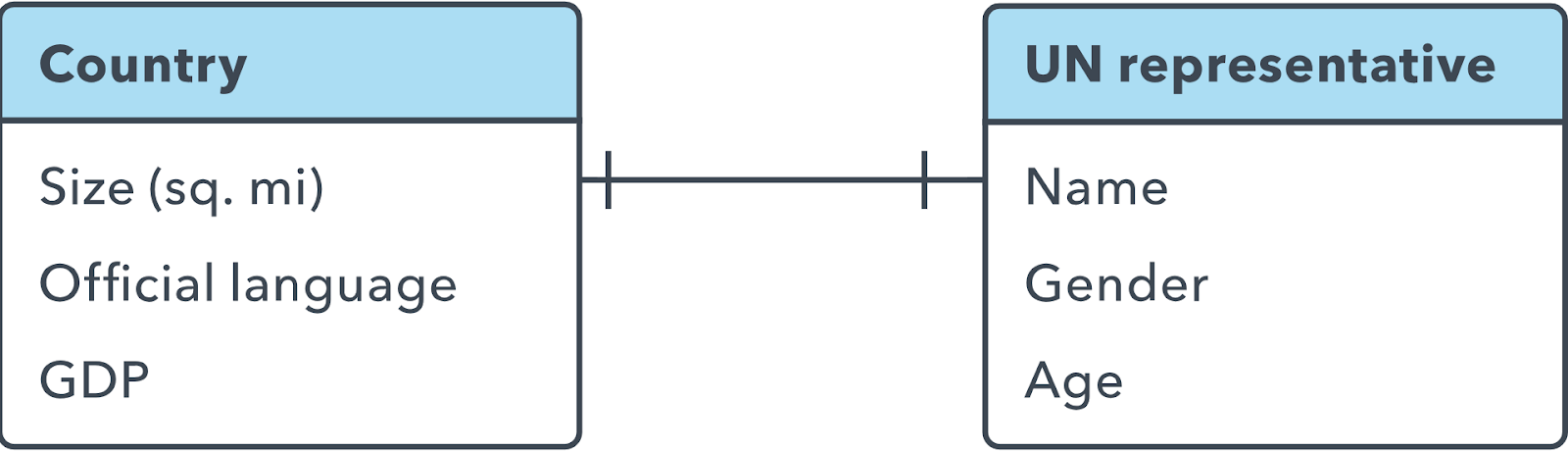
A menos que você tenha uma boa razão em contrário, uma relação 1:1 geralmente indica que seria melhor combinar os dados das duas tabelas em uma única tabela.
No entanto, convém criar tabelas com uma relação 1:1 sob um determinado conjunto de circunstâncias. Se você tiver um campo com dados opcional, como “descrição”, que esteja em branco para muitos dos registros, você pode mover todas as descrições para sua própria tabela, eliminando o espaço vazio e melhorando o desempenho do banco de dados.
Para garantir que os dados correspondam corretamente, você teria então de incluir pelo menos uma coluna idêntica em cada tabela, provavelmente a chave primária.
Relações uma para muitas
Essas relações ocorrem quando um registro em uma tabela é associado com várias entradas em outra tabela. Por exemplo, um único cliente pode ter feito muitos pedidos, ou um cliente pode ter vários livros retirados da biblioteca de uma só vez. As relações uma para muitas (1:M) são indicadas com o que é chamado de “notação pé de galinha”, como neste exemplo:
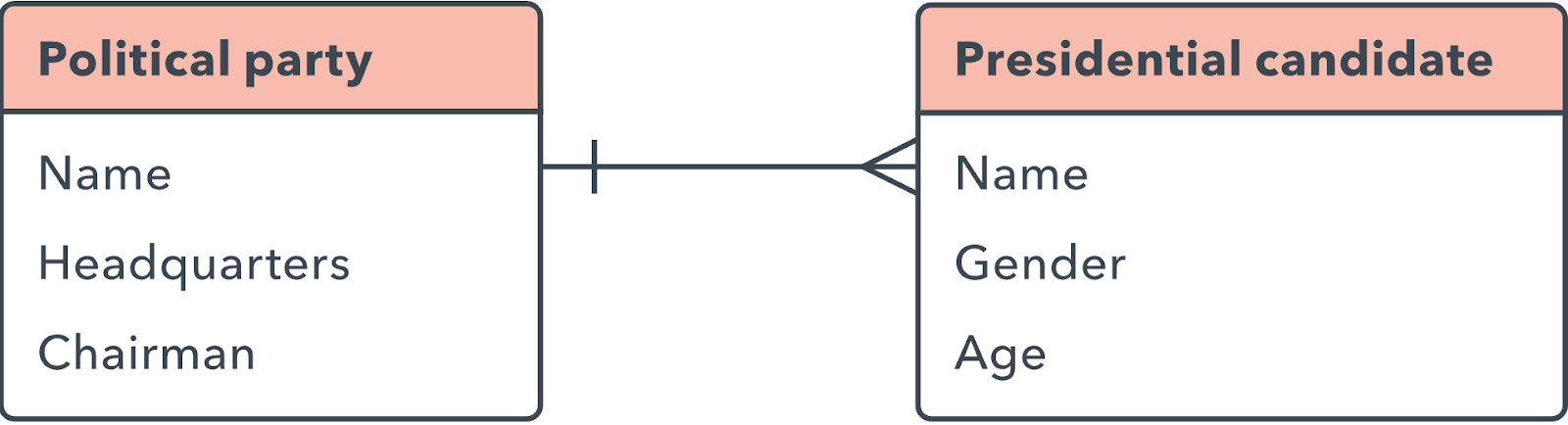
Para implementar uma relação 1:M à medida que você configura um banco de dados, basta adicionar a chave primária do lado “um” da relação como um atributo na outra tabela. Quando uma chave primária é listada em outra tabela desta forma, ela é chamada de chave estrangeira. A tabela no lado “1” da relação é considerada a tabela primária em relação à tabela secundária no outro lado.
Relações muitas para muitas
Quando várias entidades de uma tabela podem ser associadas a várias entidades em outra tabela, diz-se que elas têm uma relação muitas para muitas (M:N). Isso pode acontecer no caso de alunos e aulas, uma vez que um aluno pode ter muitas aulas e uma aula pode ter muitos alunos.
Em um diagrama ER, essas relações são retratadas com estas linhas:
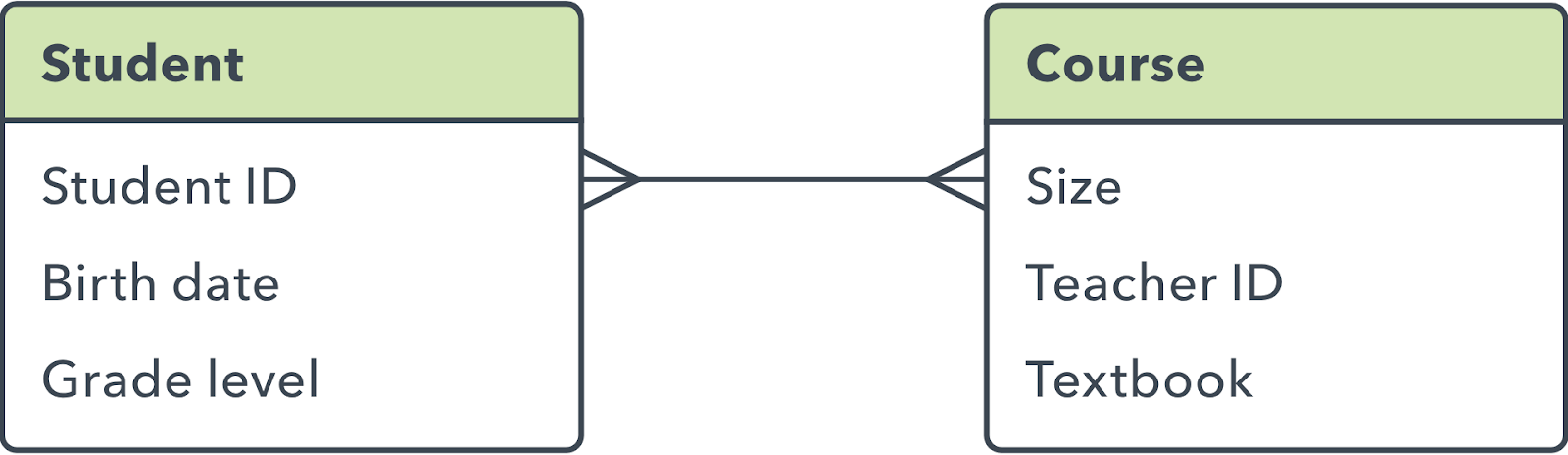
Infelizmente, não é diretamente possível implementar esse tipo de relação em um banco de dados. Em vez disso, você tem que dividi-lo em duas relações uma para muitas.
4 – Organizando as informações do banco de dados
Deu para perceber que não é tão simples assim implementar um banco de dados do zero, né? Existem muitas etapas que devem ser seguidas e um cuidado rigoroso deve ser lei durante cada passo da implementação. Felizmente, softwares empoderados com inteligência artificial já podem fazer todo o trabalho manual por si só – como é o caso do Data Cloud.
Nesse caso, o Data Cloud pode entrar em toda e qualquer parte da implementação do banco de dados na sua empresa: seja no início, ajudando a criar as estruturas basilares, até o fim, quando você já tem um banco de dados pronto, mas precisa torná-lo mais organizado e inteligente.
Outro trunfo valioso do Data Cloud é a sua capacidade de categorizar dados e transformá-los em informações acionáveis. Afinal, depois de compreender para qual motivo servirá o seu banco de dados, é hora de entender de onde esses dados vêm.
Eles podem vir de diferentes lugares, de aplicativos, sistemas, canais, data lakes, imagens, PDFs… a lista é infinita. Por isso, é preciso redobrar o cuidado para não correr o risco de duplicar dados ou mascará-los, de forma que as leituras e insights sejam indevidamente realizadas.
É aí que entra o poder do software da Salesforce, que tem a capacidade de reunir tudo, eliminando informações duplicadas e criando um perfil unificado do cliente, que ajuda a equipe a entender melhor o que o consumidor precisa hoje e antecipar o que ele pode precisar amanhã.
Isso faz com que a sua organização use todos os dados possíveis para aumentar a produtividade e oferecer um valor agregado a quem compra. Desse modo, dá para dizer que o Data Cloud elimina os silos de dados, estruturando um lugar centralizado e acessível, onde você pode encontrar todos os seus dados corporativos.
A partir da instalação do Data Cloud, você não precisa mais se preocupar com aspectos técnicos da implementação de um banco de dados. Isso porque ele atua de forma inteligente, conectando fontes de dados e extraindo o valor necessário deles para transformá-los em informação.
Para isso, o Data Cloud usa os seguintes trunfos:
Harmonização de dados
O Data Cloud ajuda você a aproveitar a integração de todos os seus dados ao nosso modelo de metadados padrão. Uma vez integrados ao modelo, as empresas podem acessar e usar qualquer um desses dados diretamente dentro dos aplicativos Salesforce — como o Sales Cloud e o Service Cloud.
Ao contrário de outras soluções de dados que são difíceis de usar ao harmonizar dados díspares em um modelo singular, a Salesforce torna a harmonização de dados incrivelmente fácil através de mapeamento por apontar e clicar e pacotes de dados pré-configurados que mapeiam automaticamente seus dados para você.
O Data Cloud facilita a ativação de seus dados
Por fim, com o Data Cloud, as equipes podem transformar dados desorganizados e difíceis de usar que estão espalhados por toda a sua empresa em um recurso unificado. O Data Cloud facilita o uso de seus dados para construir automações e processos de negócios orientados por dados.
Com integrações tanto para aplicativos Salesforce quanto para outros apps, como dados de telemetria ou sistemas de faturamento de compras, as equipes podem ativar experiências impulsionadas pelo Data Cloud em praticamente qualquer ambiente onde seu trabalho ocorre.
LEIA MAIS: Silos de dados: o que são e quais os prejuízos?
Como um banco de dados pode impulsionar a sua estratégia de IA?
Você já recebeu um email tentando vender um produto que você já havia comprado anteriormente? Ou talvez, você teve uma interação de serviço onde foi preciso responder às mesmas perguntas várias vezes com pessoas diferentes?
Bem, isso ocorre, muitas vezes, via inteligência artificial – mas não qualquer tipo de IA; geralmente através IAs que usam LLMs (ou grandes modelos de linguagem). Inclusive, essas IAs prometem eliminar aborrecimentos ao fornecer maiores níveis de compartilhamento de informações e personalização nas operações da empresa.
Contudo, o problema é que os LLMs prontos para uso, como o ChatGPT da OpenAI e o Gemini do Google, que são usados por muitas empresas, são construídos com dados genéricos universalmente disponíveis na internet. Dessa forma, como eles não têm acesso aos seus dados proprietários, qualquer IA construída a partir deles não fornecerá a nuance que seus clientes esperam – e isso pode ser um problema em termos de vendas e estratégias de marketing.
Para adaptar LLMs prontos para uso às necessidades do seu negócio, você terá que incorporar os dados da sua própria empresa ao modelo de inteligência artificial. Esse processo, chamado fine-tuning, pode até trazer melhores resultados para seus clientes. Mas é caro e demorado, e pode gerar problemas de confiança. Então, o que fazer?
Bem, existe uma maneira mais eficiente: apostar em um banco de dados vetorial, um novo tipo de banco de dados adaptado para a era da IA, que oferece todos os benefícios do ajuste fino (fine-tuning) e alivia preocupações com privacidade, ajuda a unificar dados e economiza tempo e dinheiro.
Um banco de dados de vetores pode ser conectado diretamente a um LLM ou ao comando. Ele é chamado de banco de dados de vetores porque organiza e armazena dados de uma forma que enfatiza vetores, que são tags que descrevem diferentes tipos de dados em detalhes. Dessa forma, esses descritores ajudam você a encontrar informações relevantes em um mar de dados, independentemente de sua origem.
Para facilitar a visualização, vamos propor um exemplo: empresas que gerenciam grandes cadeias de suprimentos podem usar um banco de dados vetorial para analisar e otimizar rotas de remessa. Isso porque o banco de dados vetorial tem capacidade de armazenar informações sobre padrões de tráfego, condições climáticas e fechamentos de estradas.
Agora, podemos pensar em uma empresa de SaaS que disponibiliza um chatbot de autoatendimento no seu site. Com um banco de dados vetorial, o chatbot saberá se um cliente é elegível para um upgrade ou oferta especial porque está sintetizando dados relevantes das fontes certas no momento certo. Dessa forma, um banco de dados vetorial elimina a necessidade de ajustes finos e unifica todos os dados da sua empresa com seu CRM de uma só vez.
Isso é crítico para a precisão, integridade e eficiência dos resultados, ou respostas, que você obtém dos comandos de IA. Eis o porquê: a grande maioria (90%) dos dados corporativos reside nos chamados formatos não estruturados, como PDFs, documentos de texto, vídeos, e-mails e postagens em mídias sociais, tornando-os amplamente inacessíveis a aplicativos de negócios e modelos de IA. Por não ter um formato estruturado e organizado, é quase impossível para os LLMs analisarem.
Outro ponto no qual o banco de dados vetorial pode ajudar é no uso estratégico de dados prioritários – que são o verdadeiro ouro da sua empresa. Inclusive, eles são a base para a construção de um LLM empresarial. Um banco de dados vetorial permite que a IA armazene e processe todos esses dados de uma forma que seja fácil de entender e analisar.
Ações como essa aumentam o valor Isso aumenta o valor comercial e o ROI. Como? Ele combina dados não estruturados e dados estruturados, incluindo histórico de compras, casos de suporte ao cliente e inventário de produtos, para impulsionar IA, automação e análise em todos os aplicativos comerciais. Quando você tem acesso a todas essas informações, pode tomar melhores decisões que resultam em resultados comerciais relevantes.
LEIA MAIS: Dashboard: como criar um para a sua estratégia?
Gostou de saber mais sobre Banco de Dados?
Nosso blog e Centro de Recursos estão sempre atualizados com novidades e conteúdos sobre CRM, tecnologia e inteligência de dados. Abaixo sugerimos outras leituras que podem ser úteis a você:
- Assistência Inteligente: por que seu uso é tão importante?
- Como planejar uma estratégia de APIs?
- Atendimento remoto: o que é e como usar a IA?
- O que é o Data Cloud?
Aproveite para conferir todas as funcionalidades da Salesforce e entender como o nosso CRM transforma a sua empresa. Bom trabalho e até a próxima!
Conheça o Data Cloud
Capture e gerencie todos os dados de sua empresa em tempo real e crie valor com insights acionáveis feitos por IA, tudo isso na plataforma de CRM nº 1 mundo.