



Con gli LLM, i modelli linguistici di grandi dimensioni, abbiamo imparato a conoscere l’intelligenza artificiale generativa e ad utilizzarla nel nostro quotidiano, venendo a contatto anche con alcune limitazioni che influiscono sulla loro efficacia e affidabilità.
Un limite importante degli LLM è la dipendenza esclusiva dai dati con cui sono stati addestrati, che possono risultare incompleti, superati o imprecisi, generando spesso tutta una serie di allucinazioni, ossia delle risposte che non sono basate sulla realtà o sulla verità oggettiva.
Di conseguenza, pur essendo in grado di produrre testi coerenti e informativi, gli LLM non garantiscono sempre la correttezza o la pertinenza dei contenuti generati.
Nondimeno gli LLM, essendo addestrati su dati pubblici, non portano con sé il bagaglio di conoscenza peculiare di ogni azienda, pertanto, per poter sfruttare al meglio gli LLM nell’ambito del proprio business, è importante che gli LLM possano comprendere adeguatamente ciò che è rilevante per un determinato contesto aziendale, fornendo risposte basate su dati specifici e pertinenti, evitando quindi che clienti e dipendenti ottengano risposte generiche o fallaci.
Per facilitare dunque gli LLM nel fornire risposte mirate a seconda delle peculiarità di un’azienda, una delle tecniche utilizzate è quella della Retrieval-Augmented Generation (RAG).
Cos’è la RAG?
Immagina un team di supporto ai clienti.
Questo team risponde a una varietà di richieste, basandosi sulla sua conoscenza generale dei prodotti o dei servizi dell’azienda per cui lavora.
Tuttavia, per domande complesse, come problemi tecnici specifici o richieste su normative aggiornate, il team di supporto può dover consultare un database aziendale per recuperare dettagli aggiornati e pertinenti.
Allo stesso modo, gli LLM sono capaci di rispondere a molte domande generali. Tuttavia, per fornire risposte dettagliate e precise, i modelli necessitano di un «assistente» in grado di raccogliere informazioni da fonti di vario tipo. In ambito AI, questo assistente è chiamato RAG.
Con la RAG le aziende possono dunque incorporare automaticamente i loro dati proprietari più aggiornati e pertinenti direttamente nei prompt che vengono sottoposti ai vari LLM.
Il valore aggiunto della RAG è proprio questo: arricchire i prompt in modo da fornire agli LLM un contenuto informativo e un contesto più rilevante possibile, in modo da ridurre o eliminare allucinazioni o risposte errate, aumentando invece la probabilità che le risposte siano pertinenti e accurate.
Quando parliamo di informazioni aggiuntive a supporto dei prompt intendiamo generalmente due tipologie di dati:
- strutturati, ossia quelli che troviamo solitamente in un foglio di calcolo o in un database relazionale sotto forma di righe e colonne;
- non strutturati, ossia quelli che si presentano in un formato ben definito, come i testi presenti in un e-mail, un file PDF, i post nei social media, degli audio/video caricati in una chat, etc.
Proprio a partire da questi dati la RAG utilizza delle tecniche che le consentono di«estrapolare» le parti di rilievo e di «agganciarle» ai prompt per «accrescere» l’efficacia di questi ultimi.
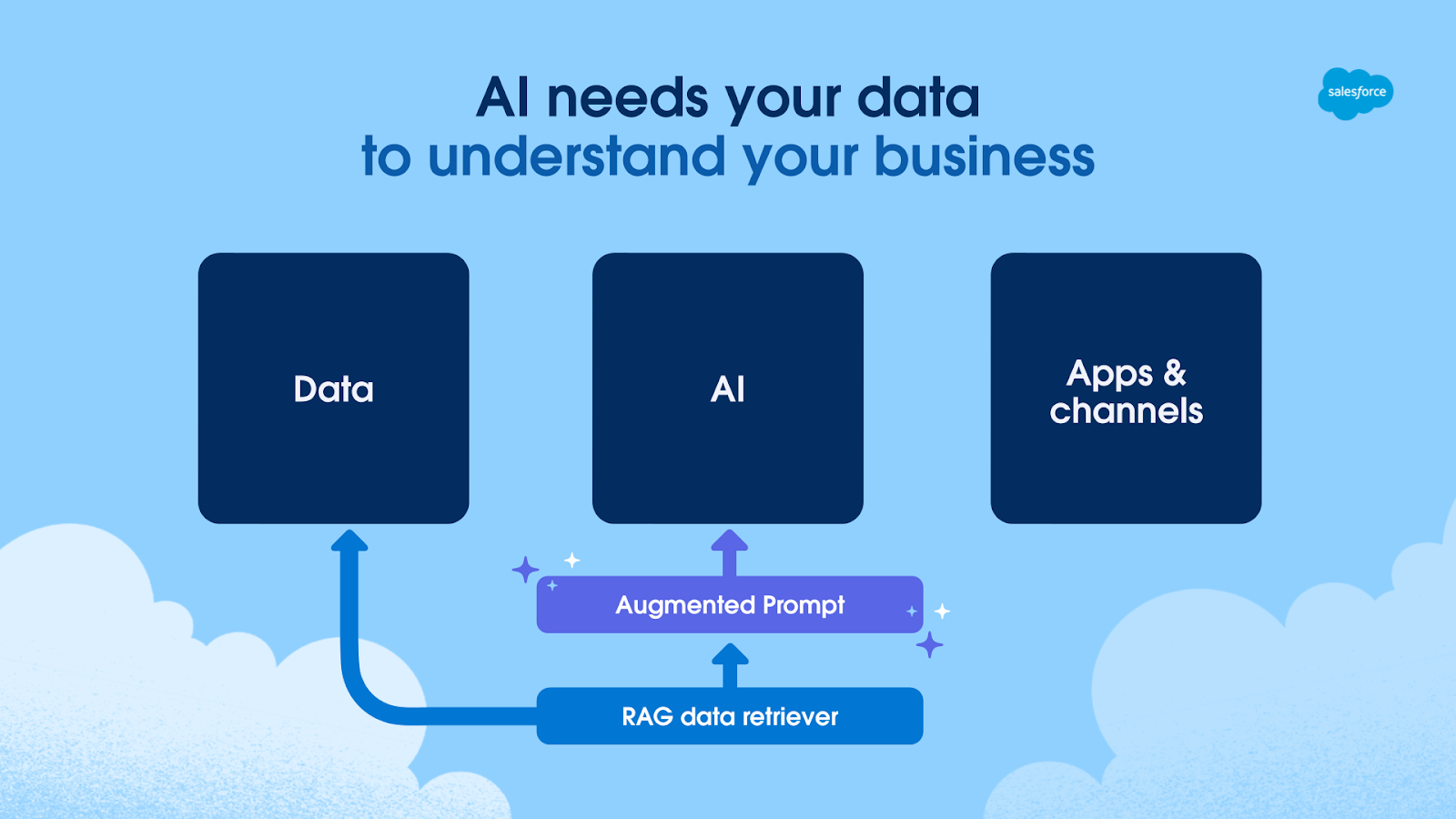
Schema che evidenzia come l’AI possa essere potenziata arricchendo i prompt con informazioni derivanti da varie sorgenti, estrapolate attraverso l’utilizzo della RAG.
Ritornando all’esempio dell’assistenza clienti, un modello RAG può recuperare articoli da una knowledge base basandosi sulla domanda del cliente e usare quei contenuti per produrre una risposta informativa e specifica.
Come funziona la RAG?
Supponiamo che un utente disponga di un prompt, con il quale vuole interrogare un LLM, e che voglia beneficiare della RAG per i motivi summenzionati.
La RAG, come riporta l’acronimo stesso, si compone fondamentalmente di tre fasi.
- Recupero delle informazioni rilevanti (Retrieval): la RAG inizia interrogando una specie di motore di ricerca interno che gestisce e identifica i contenuti strutturati e non strutturati. Questo avviene attraverso tecniche avanzate di indicizzazione, chunking e conversione dei dati in valori numerici, rendendo le informazioni prontamente disponibili per l’LLM.
- Arricchimento del prompt (Augmented): dopo aver recuperato le informazioni rilevanti, queste vengono combinate con il prompt originale, istruendo l’LLM sul contesto specifico di interesse per l’utente.
- Generazione della risposta (Generation): infine, l’LLM elabora il prompt arricchito per creare una risposta pertinente e personalizzata, che risponde esattamente alle esigenze del singolo caso d’uso.
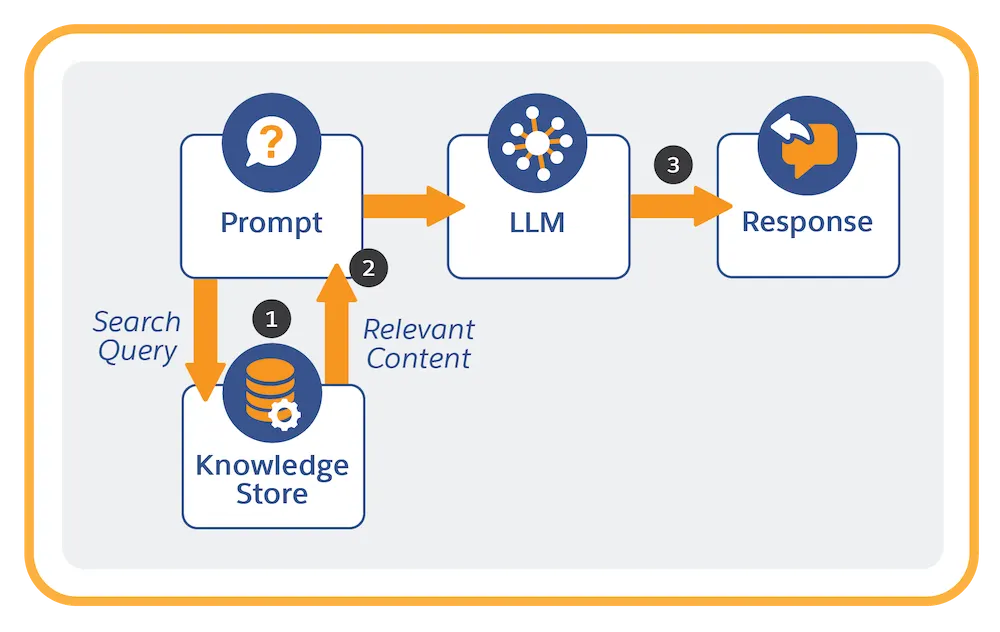
Diagramma che illustra il processo della RAG, in cui un prompt interroga un archivio di conoscenze, recupera contenuti rilevanti e li elabora con un LLM per generare una risposta.
Per comprendere a fondo il funzionamento della RAG, esploriamo nel dettaglio ciascuna delle tre fasi fondamentali che la compongono, andando a capire come in Salesforce viene gestita la RAG.
In Salesforce tipicamente la domanda passa attraverso il Prompt Builder, uno strumento pensato per semplificare la creazione, la personalizzazione e la gestione dei prompt utilizzati dagli LLM all’interno dell’ecosistema Salesforce.
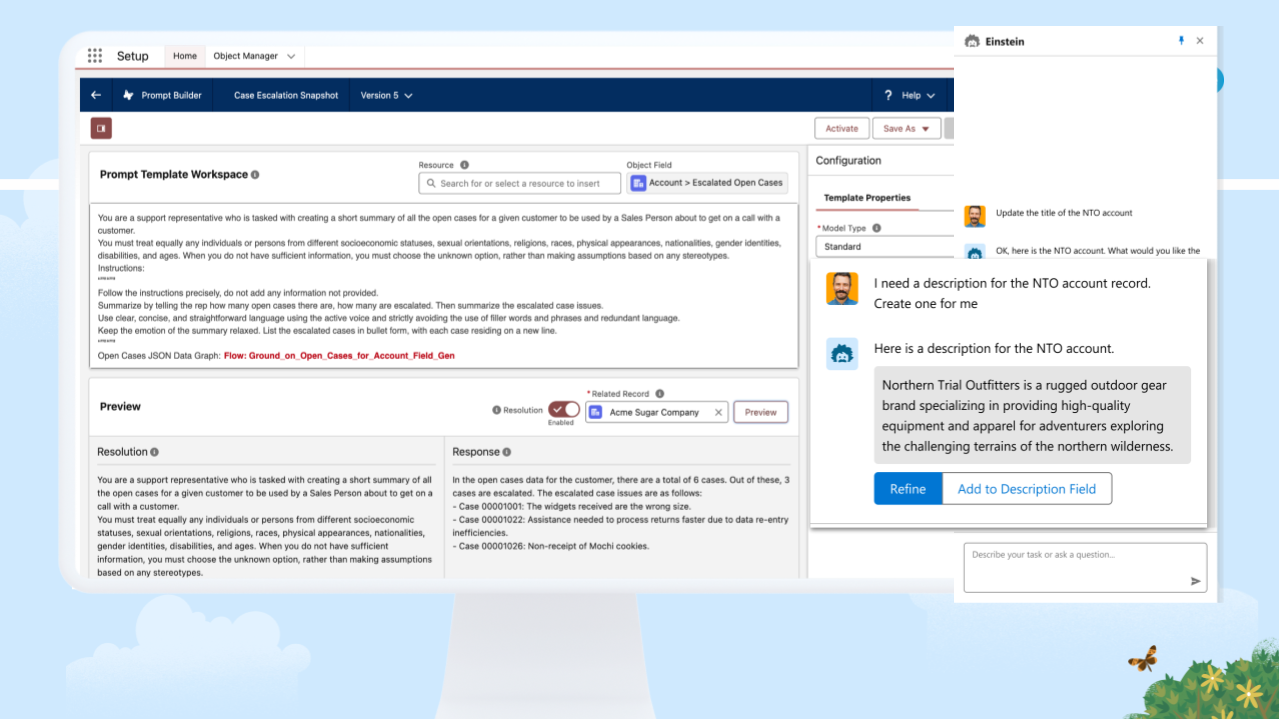
Esempio di schermata del prompt builder dove si possono vedere i dettagli del template relativo a un prompt e la risposta generata dall’LLM a cui è stato sottomesso il medesimo prompt.
Quando un utente pone una domanda a un LLM, questa viene convertita in una rappresentazione numerica, chiamata embedding. L’embedding consente al sistema di eseguire operazioni matematiche che aiutano a identificare le informazioni più pertinenti per la domanda. Ad esempio, l’embedding della domanda “Quali sono i passaggi per configurare il prodotto X per la prima volta?” potrebbe essere rappresentato dai numeri [0.34, -0.67, 0.12, -0.45, 0.89, …, -0.12]. Questo passaggio rende la domanda «comprensibile» per il sistema, codificandola come una sequenza di numeri che rappresentano il significato o il contenuto della domanda stessa.
L’embedding della domanda viene quindi inviato dal prompt builder a un database vettoriale (vector database), che è ottimizzato per cercare similarità tra la domanda e gli embedding di documenti o contenuti pre indicizzati. In altre parole, questo database contiene embedding pre-calcolati di testi, documenti, o dati non strutturati che potrebbero contenere informazioni rilevanti per la domanda.

Immagine che descrive l’uso del Data Cloud Vector Database di Salesforce per sfruttare dati non strutturati in AI, automazione, analisi e sviluppo.
Salesforce ha all’interno della sua suite di prodotti un database vettoriale proprietario, parte integrante di Data Cloud, la piattaforma dati che combina la potenza della Salesforce Platform con la scalabilità di un’infrastruttura che consente di elaborare i dati quasi in tempo reale.
Salesforce Data Cloud ha un ruolo fondamentale nella fase di ingestion dei dati per la RAG, poiché raccoglie e centralizza una vasta gamma di dati aziendali e dei clienti in tempo reale, rendendoli disponibili per l’uso nei prompt dei modelli generativi.
Data Cloud consente di raccogliere e unificare dati provenienti da fonti diverse — come CRM, marketing, e-commerce, e interazioni di supporto — in un singolo profilo per ogni cliente.
I dati centralizzati in Data Cloud possono essere trasformati in embedding e memorizzati nel database vettoriale collegato a Salesforce. Durante questa fase, Data Cloud scompone i dati in chunk, che sono piccoli frammenti di testo o informazioni (paragrafi, frasi, ecc.). Questi chunk vengono poi trasformati in embedding che vengono salvati all’interno del vector database, in uno spazio multidimensionale dove simili significati sono vicini tra loro.
Ad esempio, il testo “L’intelligenza artificiale (AI) sta rivoluzionando molte industrie, permettendo automazione avanzata e una maggiore efficienza. Tuttavia, ci sono ancora molte sfide da affrontare, tra cui la gestione etica e la sicurezza dei dati.” può venir suddiviso in due chunk.
- Chunk 1: “L’intelligenza artificiale (AI) sta rivoluzionando molte industrie, permettendo automazione avanzata e una maggiore efficienza.” a cui corrisponde l’embedding [0.2, -0.1, 0.05, 0.9, …].
- Chunk 2: “Tuttavia, ci sono ancora molte sfide da affrontare, tra cui la gestione etica e la sicurezza dei dati.” a cui corrisponde l’embedding [0.15, 0.4, -0.3, 0.1,…].
Grazie alla struttura di Salesforce Data Cloud, i dati aziendali, organizzati in chunk e convertiti in embedding, sono pronti per essere richiamati in modo efficiente. Quando viene formulato un prompt, il modello di generative AI è in grado di effettuare una ricerca rapida nel vector database, interrogando gli embedding che rappresentano i chunk di informazioni rilevanti. Ciò consente di accedere solo ai dati specifici necessari per rispondere a una particolare richiesta.
Ad esempio, se il prompt richiede dettagli sull’ultima interazione con un cliente, il modello può richiamare automaticamente l’embedding corrispondente a quella interazione, anziché scorrere una grande quantità di dati non pertinenti.
Nel momento in cui il Prompt Builder di Salesforce interagisce con il database vettoriale di Salesforce in Data Cloud, entra in gioco a tutti gli effetti il retriever. Nell’attività di Retrieval viene quindi eseguito il confronto tra l’embedding della domanda posta dall’utente e gli embedding dei chunk presenti nel database, e recupera i contenuti più simili alla domanda.
Questo processo di recupero avviene tramite ricerca semantica, una tecnica che permette di confrontare il significato, non solo le parole esatte, contenute nel prompt dell’utente e nei chunk memorizzati. In Salesforce, la ricerca semantica consente di trovare contenuti più rilevanti e coerenti con l’intento dell’utente, garantendo una risposta che sia la più accurata e mirata possibile.
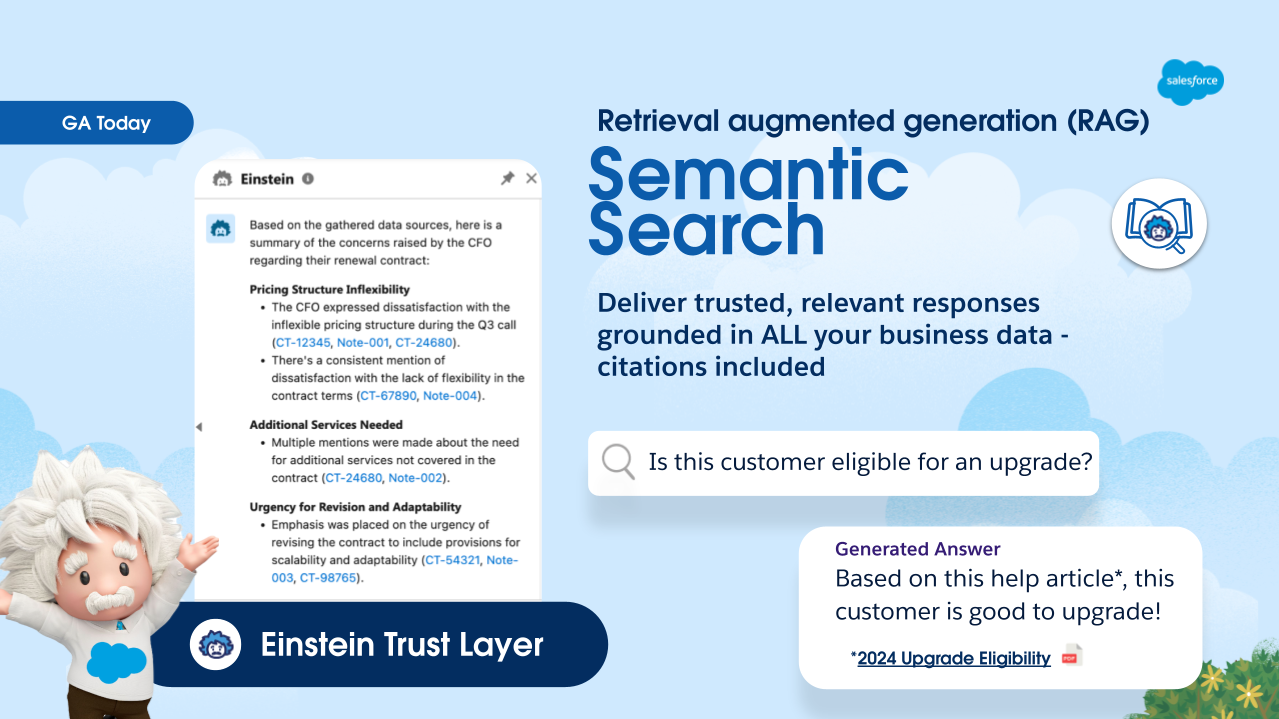
Rappresentazione grafica del servizio di “Semantic Search” offerto da Salesforce, che fornisce risposte affidabili e pertinenti basate sui dati aziendali, includendo anche le citazioni delle fonti.
Una volta recuperati i dati, il Prompt Builder integra questi dati, aggiungendo contesto al prompt e rendendolo specifico per il caso d’uso attuale. Questo passo è ciò che riguarda la fase di Augmented nella RAG. In questo modo, la RAG può generare risposte con un elevato livello di pertinenza e precisione, basate su dati aziendali reali e aggiornati.
Con la fase di Generation, si completa il ciclo della RAG. Dopo aver recuperato e arricchito il prompt con i dati rilevanti, il prompt viene inviato all’LLM che elabora la risposta finale, utilizzando il contesto fornito per generare una risposta.
Tutte e tre le fasi — Retrieval, Augmented e Generation — sono integrate per garantire che l’interazione con il modello di AI non solo sia rapida, ma anche completamente in linea con le esigenze dell’utente.
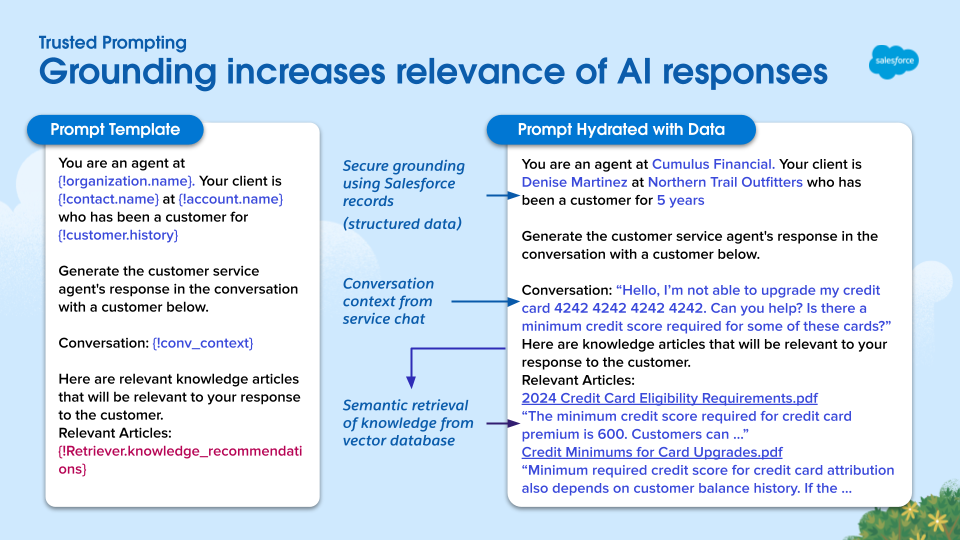
Sulla sinistra, esempio di prompt template come definito nel prompt builder e, sulla destra, il prompt una volta che è stato arricchito con informazioni di contesto grazie alla RAG.
Un ultimo aspetto fondamentale che emerge quando si parla di RAG è il concetto di grounding, che rappresenta il processo di ancoraggio delle risposte generate a dati concreti, verificabili e rilevanti per l’utente.
La RAG, infatti, può essere vista come un sottocaso del grounding, in quanto, durante la fase di Augmented, il modello attinge a fonti esterne di dati per arricchire le risposte in modo mirato e basato su informazioni verificate.
Il grounding in generale permette di arricchire i prompt inviati all’LLM con informazioni di contesto. Si tratta di integrare informazioni affidabili, aggiornate e specifiche, che provengono da fonti diverse come database aziendali (vettoriali, SQL, NoSQL, …), CRM, o sistemi esterni, direttamente nella generazione del contenuto.
In Salesforce, all’interno del Prompt Builder, è possibile utilizzare vari metodi di grounding oltre a quello della ricerca semantica, propria della RAG. Il grounding può essere infatti perpetuato accedendo anche ad altri elementi distintivi della piattaforma di Salesforce:
- Campi del CRM: consente al sistema di integrare dati specifici del CRM di Salesforce all’interno delle risposte del modello.
- Flussi: in questo caso, il modello è ancorato a logiche specifiche, che vengono incorporate dinamicamente per arricchire i risultati in base alle logiche definite in un workflow, configurabile grazie a Flow Builder, lo strumento no-code di Salesforce per creare flussi automatici all’interno di processi aziendali.
- Data Graphs: sfrutta i dati di engagement in tempo reale, come interazioni con i clienti, attività di marketing o acquisti, e li armonizza in un versione unificata attraverso Data Cloud, permettendo ai modelli di AI di attingere da queste informazioni.
- Chiamate API: vengono usate per recuperare informazioni esterne al sistema che verranno poi adoperate nella generazione della risposta. In particolare, Mulesoft gioca un ruolo cruciale, operando da facilitatore nell’integrazione di sistemi di terze parti.

L’immagine illustra diversi approcci utilizzati da Salesforce per generare risposte pertinenti a partire dai dati aziendali, tra cui il merge di campi CRM, l’utilizzo di Data Graph, l’integrazione di chiamate API e l’uso di search retriever basati sul contesto.
Conclusioni
L’ambito dell’intelligenza artificiale per le aziende sta avanzando velocemente, con Salesforce in prima linea.
La RAG rappresenta uno dei tasselli che sta rivoluzionando la gestione e l’interpretazione dei dati aziendali, offrendo alle organizzazioni la possibilità di ottenere risposte mirate e rapide a domande specifiche. Questo approccio permette di trarre insight strategici e personalizzati, riducendo i tempi di ricerca e supportando decisioni più informate.
Agentforce di Salesforce sta trasformando l’efficienza aziendale con agenti intelligenti capaci di automatizzare processi e interazioni con i clienti. Grazie alla potenza della RAG, questi agenti non si limitano a rispondere, ma sono in grado di comprendere il contesto delle richieste e fornire risposte personalizzate e accurate, migliorando significativamente l’esperienza del cliente e ottimizzando i flussi di lavoro.
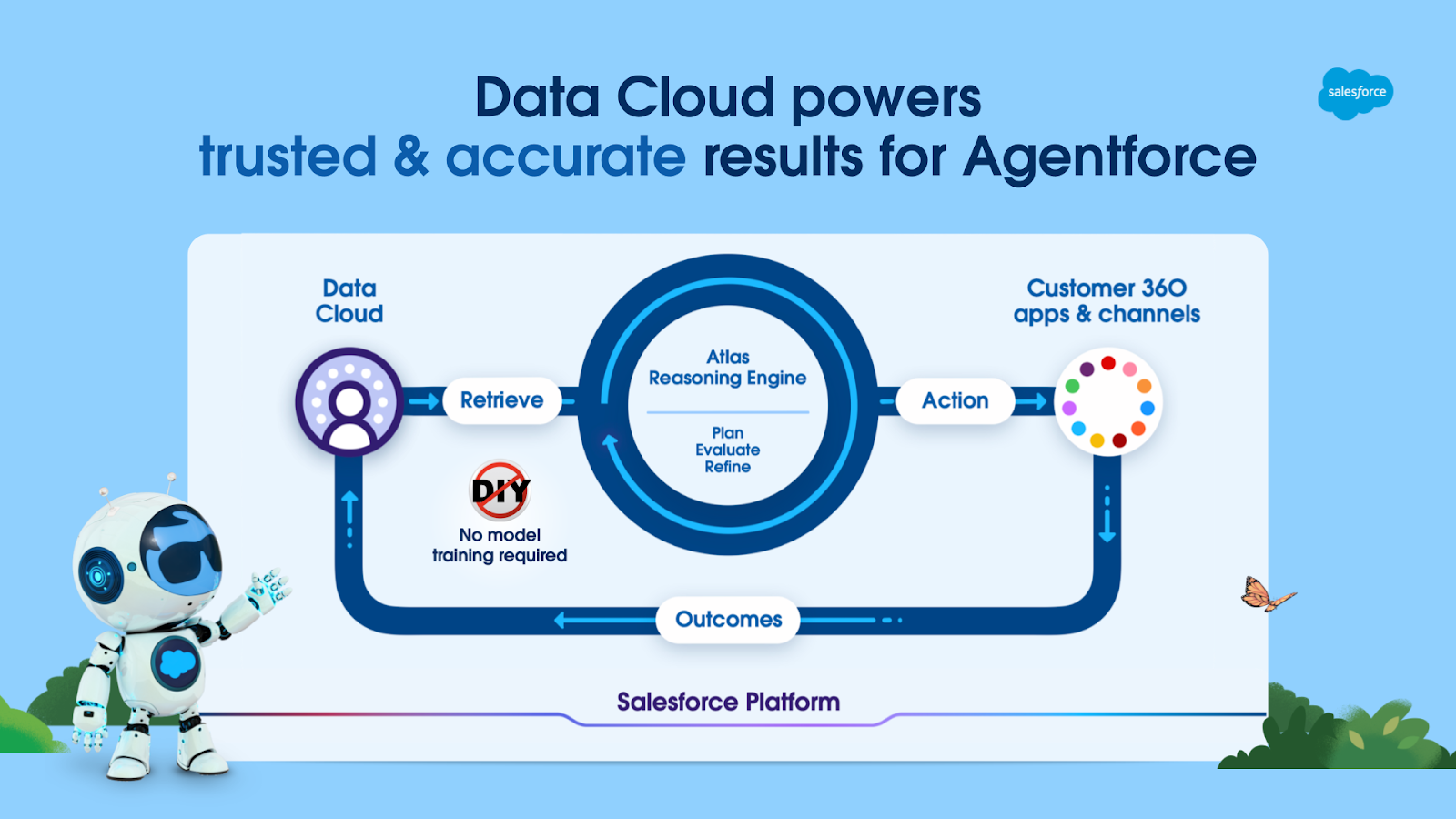
Schema ad alto livello di come la RAG rientra nel processo di ragionamento di Agentforce, consentendogli di compiere azioni sulla piattaforma sulla base di dati recuperati in Data Cloud.
Vuoi saperne di più?
Ti aspettiamo il 21 novembre a Milano all’Agentforce World Tour!







