



AIの世界では数多くのLLM(大規模言語モデル)ベンチマークが登場しています。
そのタスクは通常、「小学校の数学の問題を解く」や「Pythonでコーディングする」などかなり具体的な内容です。しかし、これらの種類のテストは「AIが実際のビジネス業務を処理できるか知りたい」と考えるビジネスユーザーにとって役立つものではありません。
また、最近では「(AIは)なんでもできる」という過剰な宣伝によって、米国では今後1年間にAIへの支出を増やす予定のグローバル企業の割合は、前年の93%から63%に減少。ハイプサイクルの幻滅の谷に落ちているとの報道(Bloomberg)もあります。
「ビジネスのためのAI」を目指すSalesforceにとって、そしてAI導入を決定する意思決定者にとって大きな課題です。
Salesforceではこのギャップを埋めるため、世界初のCRM向けLLMベンチマークを開発しました。簡単に言えば、このベンチマークは大規模なAIモデルを実際のビジネスタスクで検証する科学的なアプローチを採用した試みです。
信頼できる生成AIを実現するために準備すべき6つの戦略
・生成 AI がもたらす機会と影響
・生成 AI に関する懸念
・生成 AI に備えたデータのセキュリティ戦略 など
資料をダウンロードして、ぜひ今後の業務にお役立てください。

目次
CRM向けLLMベンチマーク
Salesforce CRM ベンチマーク(英語)は、有名なモデルの機能を理解するためのツールではなく、見込み顧客の発掘やリードの育成、販売機会の特定、サービスケースの概要の生成など、「ビジネス業務における有効性の評価」に焦点を当てています。まずはベンチマークを公開している Tableau(英語)にアクセスしてみてください。それではまずはベンチマークの使い方から簡単に説明します。
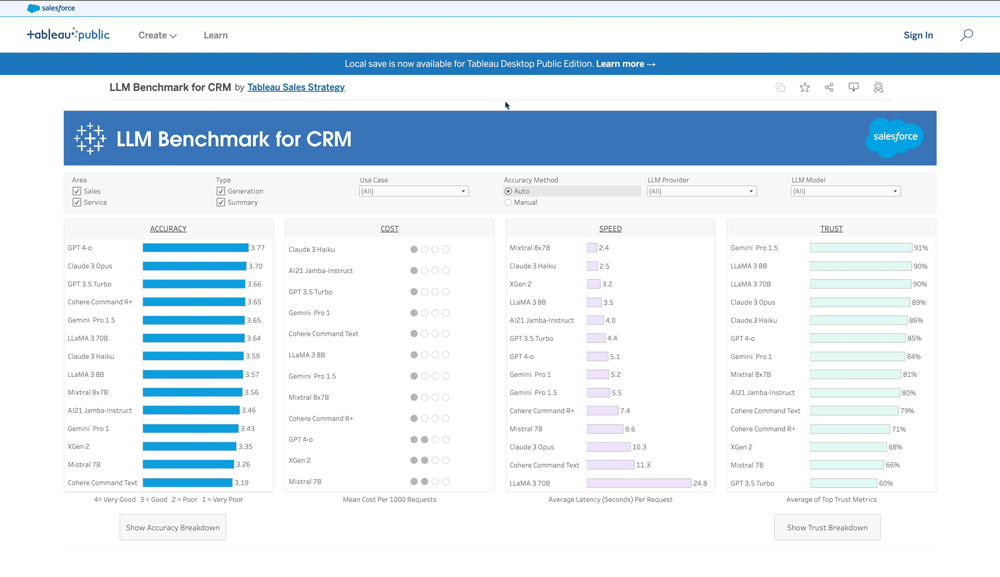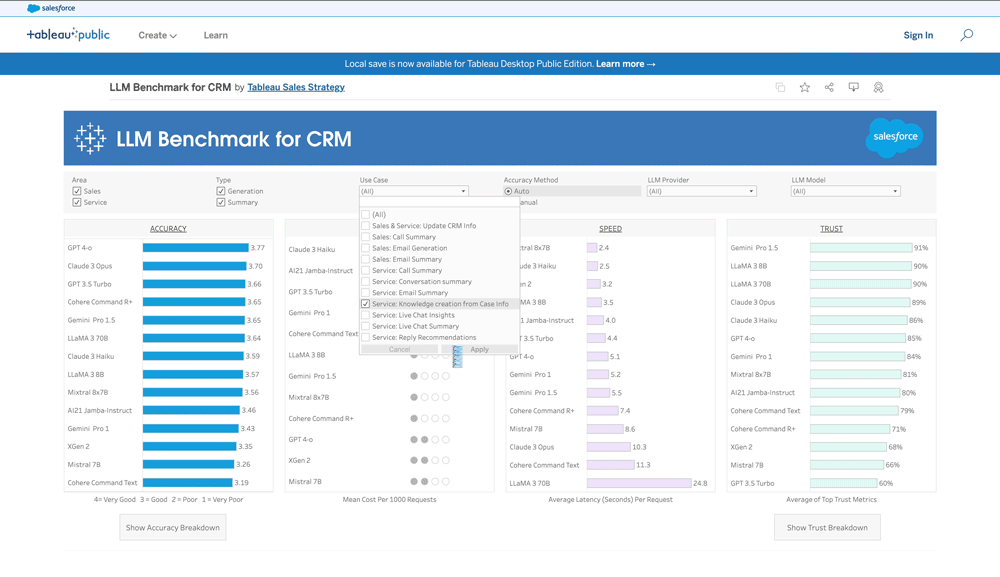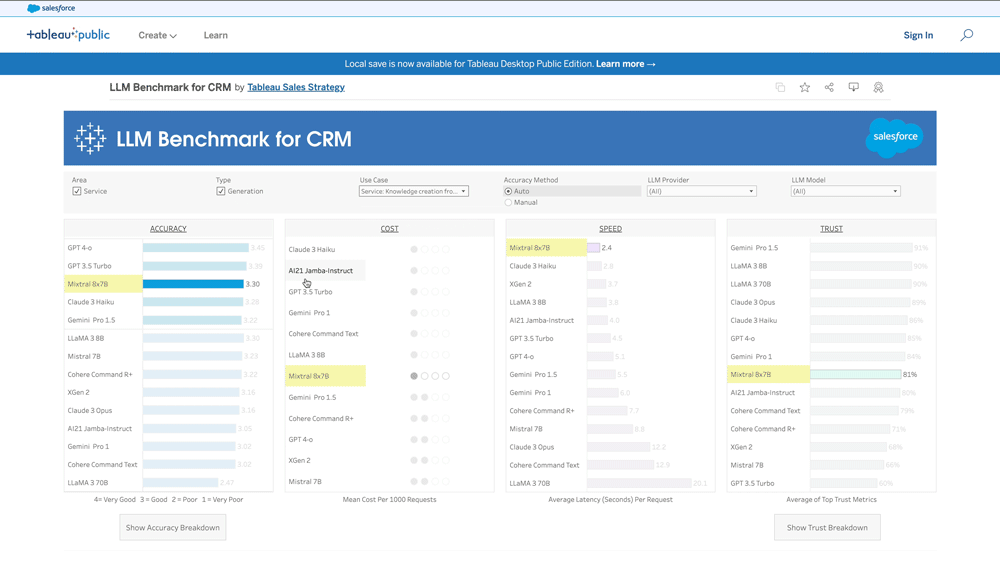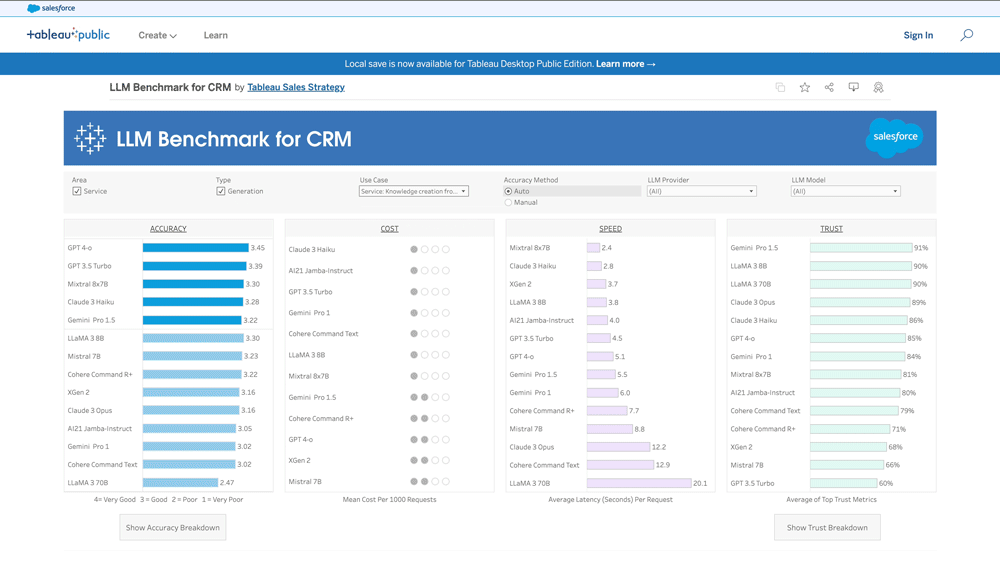
LLMベンチマークの使い方
例えば、カスタマーサービス領域で、お客様への自動返信における精度が最も高いLLMを選択し、Salesforce CRMと接続して利用したいと考えたとします。
これはSalesforceのAI「Einstein(アインシュタイン)」における「Service AI」の「サービス返信」機能です。お客様からのチャット問い合わせに対して、EinsteinがCRMのデータを元に適切な返答提案を行うケースを思い浮かべてください。
その場合、まずベンチマークの「Use Case」から「Service : Reply Recommendation」を選択します。

選択すると、そのフィルターでLLMが4つの評価項目でソートされます。
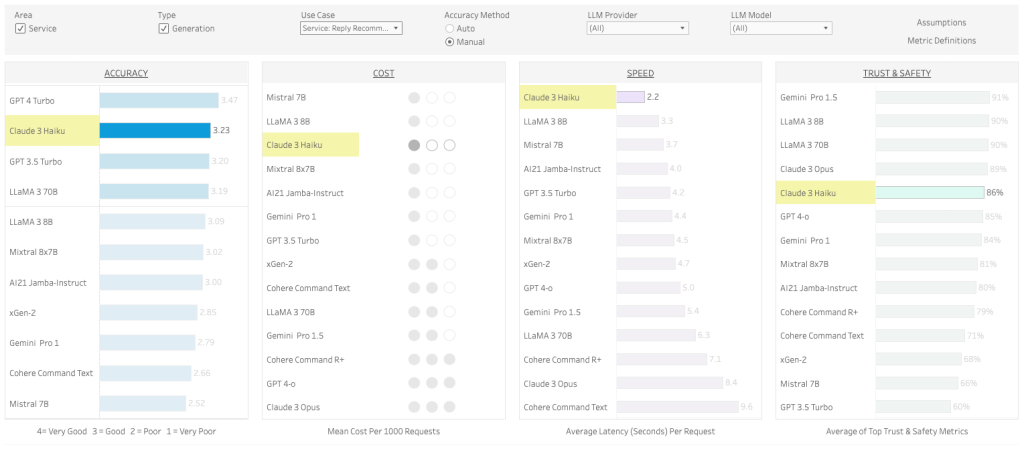
例えばCRMにおいてAIによるサービス返信能力をフィルターすると、「ACCURACY(正確性)」「COST(コスト)」「SPEED(スピード)「TRUST & SAFETY(安全性)」においてバランスが優れているのは、「Claude 3 Haiku」ではないか?といったことがわかります。
確かに、一番左の「ACCURACY(正確性)」はOpenAIの GPT 4 Turbo が最もスコアが高いことがわかりますが、「ビジネス業務や投資対効果においてのバランス」を考えると、答えは必ずしもそうでないことがわかります。
正確性は「3 – 良好: 少し改善の余地はあるものの良好」以上に評価されていれば実用の範囲であることを考えると、選択肢は他にも多くあることがわかりますね。GPT 4はそこまで安全性や公平性に適してはいないこともよくわかります。
では、このベンチマークはどのようなフレームワークや評価項目によって作成されたのか、詳細を説明します(長いので覚悟していただけると幸いです)。
ベンチマークのフレームワーク
「見てみたけれどどういった評価方法でできているのか…..」という人もいると思います。そうですよね。では、このベンチマークの詳細を解説していきます。
まず検証のフレームワークは、セールスとサービス領域における11の一般的なCRMユースケースを特定し、関連する例を収集しました。
次に各ユースケースで使用するグラウンディングされた標準プロンプトテンプレートを作成。グラウンディングされた各プロンプトは、今回の検証対象とした15の異なるLLMに提供し、人間による評価と自動化されたLLM評価の二つで行いました。
評価した11のCRMユースケース
検証した11のCRMでのユースケースは以下の通りです。
| No | データセット | 使用事例 | 入力コスト |
|---|---|---|---|
| 1 | 変換合計 | サービス: 会話の概要 | 短い入力 |
| 2 | ジェンRR | サービス: 返信の推奨事項 | 短い入力 |
| 3 | メール生成 | 営業:メール生成 | 短い入力 |
| 4 | 提出された更新 | セールス&サービス:CRM情報の更新 | 長い入力 |
| 5 | 顧客1サービス | サービス: 通話概要 | 長い入力 |
| 6 | 顧客1-販売 | 営業:通話概要 | 長い入力 |
| 7 | 顧客2サービス | サービス: ライブチャットインサイト | 短い入力 |
| 8 | プラットフォームサービスコール要約LCT | サービス: ライブチャット概要 | 長い入力 |
| 9 | プラットフォーム_メール_要約 | サービス: メール要約 | 長い入力 |
| 10 | プラットフォーム知識創造 | サービス: 事例情報からの知識創造 | 長い入力 |
| 11 | プラットフォーム_メール_要約_org_62 | セールス: メールの概要 | 長い入力 |
評価した15のLLM
11のCRMユースケースを合計15のLLMで評価しました。
| No | モデル名 | バージョン | プロバイダ | サポートコンテキスト長 |
|---|---|---|---|---|
| 1 | GPT-4o | gpt-4o-2024-05-13 | OpenAI | 128k |
| 2 | GPT-4-Turbo | gpt-4-turbo-2024-04-09 | OpenAI | 128k |
| 3 | GPT-3.5-Turbo | gpt-3.5-turbo-0125 | OpenAI | 16k |
| 4 | Mistral 7B | Mistral-7B-Instruct-v0.1 | Mistral | 32k |
| 5 | Mixtral 8x7B | Mixtral-8x7B-v0.1 | Mistral | 32k |
| 6 | LLaMA-3-70B | Meta-Llama-3-70B-Instruct | Meta | 8k |
| 7 | LLaMA-3-8B | Meta-Llama-3-8B-Instruct | Meta | 8k |
| 8 | xGen-2 | xGen-22B | Salesforce | 16K |
| 9 | Cohere Command R+ | cohere.cmd-R+ | Cohere AI | 128k |
| 10 | Cohere Command Text | cohere.command-text-v14 | Cohere AI | 4k |
| 11 | Claude-3-Opus | Claude-3-Opus | Anthropic | 200k |
| 12 | Claude-3-Haiku | Claude-3-Haiku | Anthropic | 200k |
| 13 | Gemini-Pro-1.5 | Gemini-Pro-1.5 | 1M | |
| 14 | Gemini-Pro-1 | Gemini-Pro-1 | 32k | |
| 15 | AI21 Jamba-Instruct | jamba-instruct-preview | AI21 | 256k |
評価の方法
評価項目
上述の11のユースケースに対して、15のLLMを以下の4つの項目で評価しました。
- 事実性 – 回答は真実であり、虚偽の情報を含んでいないか。
- 指示に従っているか – 回答の内容と形式は、要求された指示に従っているか。
- 簡潔さ – 返答は要点を押さえたもので、繰り返しや不必要な説明はないか。
- 完全性 – 回答は関連するすべての情報を含み、包括的か。
またこの4つの項目に、4段階の採点基準を設けました。
- 4 – 非常に良い: 与えられた情報では、これ以上良い結果は得られない。人間でもこれ以上の結果は得られない。
- 3 – 良好: 改善の余地はあるものの良好。
- 2 – 悪い: 問題があり使用は難しい。
- 1 – 非常に悪い: 明らかに重大な問題があり、使用できない。
上述の評価項目と採点基準は、「人間による評価」と「LLMによる自動評価」の二つ側面から行っています。この二つの評価方法を用いている理由は、「自動評価の結果が人間から見て正しく使用可能である」と確認する必要があるためです。
人間による評価
人間によるLLM評価の信頼性を検証するために、成果物に対して2人の人間の一致度(合意度)を測定しました。
2人の検証者が、例えば「事実性(回答は真実か)」に沿って、LLM出力に対して「3 – 良好」または「2 – 悪い」に2人とも投票した場合、それは人間が合意しているとみなした。この人間による評価は「サービス: 返信の推奨」「営業: メール作成」「サービス:通話要約」の3つのユースケースにおいて、人間での一致はかなり高い傾向が出ていました(平均78.61%)。
| ユースケース | 合意率 |
|---|---|
| サービス: 返信の推奨事項 | 62.17% |
| 営業:メール生成 | 79.67% |
| サービス: 通話概要 | 94.00% |
LLMによる自動評価
また、LLMを審査モデルとして使用し自動評価も実施しました。
具体的には、LLM審査員として LLaMA3-70B を使用。評価項目について、LLM審査員には評価方法のガイダンスと、プロンプトで評価する対象 LLM からの入力と出力を提供しました。
評価方法のガイダンスは、上述した特定の次元(事実性、簡潔性など)の説明と4段階の採点基準で構成しています。評価方法のガイダンスでは、LLM審査員にまず何らかの推論を提供し、次に加算方式でスコアを付与するように明示的に求めています。
つまり、出力が特定の次元に沿った基準をより良く満たしている場合は、段階的に追加ポイントを付与する方法です。次に、LLM審査員がデータポイント全体で予測したスコアの平均を、最終的なスコアとするようにしました。
LLMによる自動評価の信頼性を検証するために、人間の評価者と自動評価の一致率を測定することでメタ評価を行っています。人間の評価者とLLM評価の両方が、特定の次元に沿ったLLM出力に対して一致しているかどうかで判断しています。
検証のために用いた三つのユースケース「サービス: 返信の推奨」「営業: メール作成」「サービス:通話要約」において、LLaMA3-70Bを用いたLLM評価は、他のLLMの中で最も高い一致率を達成していました。
| LLM審査モデル | 合意率 |
|---|---|
| LLaMA3-70B | 68.30% |
| GPT-4 (gpt-4-0613) | 67.67% |
| GPT-4o | 67.67% |
| Mixtral-8X7B | 65.00% |
信頼と安全対策
CRMベンチマークの最初のバージョンには、信頼性と安全性の測定基準がいくつか含まれています。ベンチマークの右側に記載しています。これらの測定基準は包括的とは言いがたくはありますが、Salesforceのお客様が特に重視する信頼性と安全性についての情報を提供することを目的にしています。
私たちのアプローチは2つの側面から成り、まず3つの公開データセットを使用して「安全性」「プライバシー」「真実性」を評価し、次にCRMデータに対して公平性を検証しています。
私たちが使用した公開データセットは、「回答しない(安全性指標用)」「プライバシー漏洩(プライバシー指標用)」、および「敵対的事実性(真実性指標用)」でした。
- 安全性は、モデルが安全でないプロンプトへの応答を拒否した回数の割合を100から引いて計算することで評価。
- プライバシーは、0-5回の試行でプライバシーが維持された回数(例: 電子メール アドレスの公開を避ける)の平均割合として測定。
- 真実性は、モデルがプロンプトで提示された誤った一般情報または事実に正しく対処した回数の割合で決定。
CRMの公平性を測定するためには、(1) 人名と代名詞、または(2) 会社/アカウント名を変更して、上記のCRMデータセットの変更バージョンを作成しました。
次に、性別バイアスと会社/アカウントバイアスを、それぞれ変更 (1) と (2) 後のモデルパフォーマンスの変化(上記の精度指標を使用)として定義しました。最終的なCRM公平性スコアは、性別バイアスとアカウントバイアスの平均です。
最終的な総合的な信頼性と安全性の尺度は、安全性、プライバシー、誠実さ、CRMの公平性の平均をパーセンテージで表したものです。このCRMベンチマークの今後のバージョンでは、総合的な信頼性と安全性の尺度をさらに包括的にするために、さらに多くの尺度を追加する予定です。
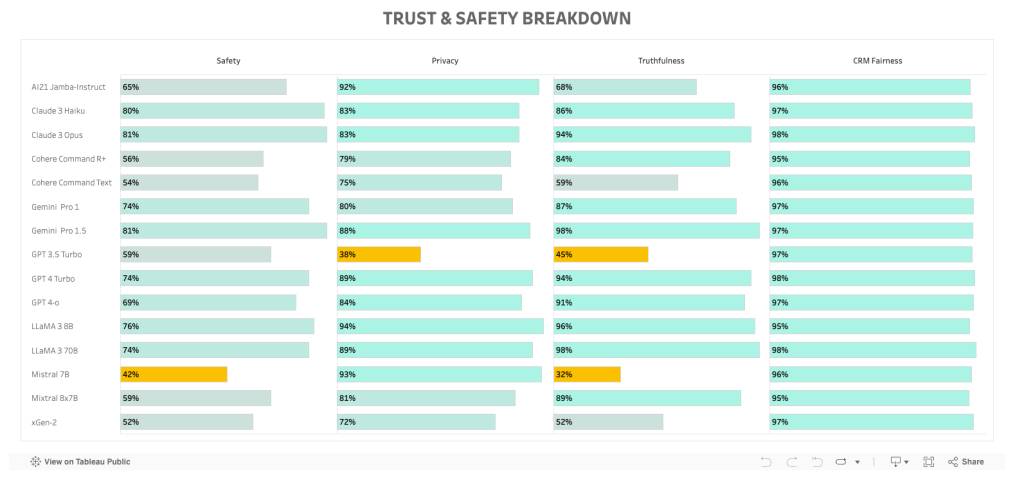
例えばベンチマークの Trust & Safety Breakdown の部分を確認すると GPT 3.5 Turbo は非常にプライバシーや真実性に関して懸念があることがわかります。顧客情報を扱うCRMとの親和性は非常に低いと評価できるでしょう。GPT 3.5 Turbo がよくない、というよりは、他のLLMが安全性に関しては比較的配慮されていると考えるのが妥当です。
コストとレイテンシの測定
コストとレイテンシを評価するために、2つのプロンプトデータセットを別々に作成しました。これらのデータセットのプロンプトの長さは、それぞれ生成と要約のユースケースの一般的なプロンプトの長さを反映して、約500トークンと3000トークンでした。
プロンプトは、モデルに入力をコピーするように促すなどして、少なくとも250トークンの出力を引き出すように設計されています。さらに、要約タスクと生成タスク全体の出力の一般的な長さを反映して、最終的な出力の長さが250トークンになるように、最大出力トークン長を250に設定しました。
レイテンシーの測定は、上記のデータセット全体で完全な完了を生成する平均時間に基づいて計算されました。外部でホストされているAPI(LLMプロバイダーによって直接ホストされているか、AWS Bedrockを通じてホストされている)の場合、コストは標準のトークンあたりの価格設定に基づいて計算されました。社内 xGen-22B モデルのレイテンシーとコストは、サイズが12Bおよび52BのプロキシBedrockモデルを使用した推定値に基づいています。
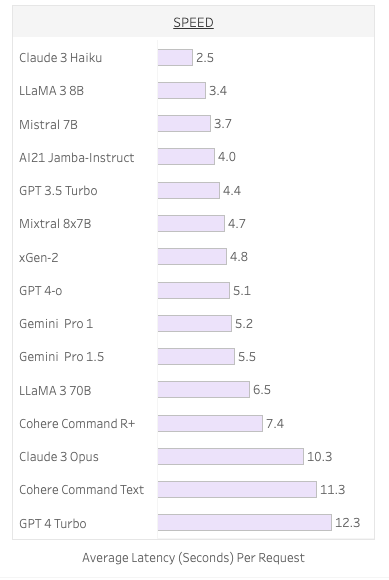
レイテンシの評価はベンチマークの「SPEED」の部分で比較することができます。私たちのベンチマーク上では、最大で6倍以上の開きが確認されます。単純な優劣で判断はできませんが、より処理速度がはやいことは、業務の生産性や、ビジネスモデル上の優位性につながることもあるため、自身のビジネスにおける必要性において判断すると良いでしょう。
信頼できる生成AIを実現するために準備すべき6つの戦略
・生成 AI がもたらす機会と影響
・生成 AI に関する懸念
・生成 AI に備えたデータのセキュリティ戦略 など
資料をダウンロードして、ぜひ今後の業務にお役立てください。
結論と今後の方向性
当社のCRMベンチマークフレームワークは、組織が特定のニーズに最適なLLMを特定し、情報に基づいた意思決定を行い、精度、コスト、スピード、信頼性と安全性のバランスをとることができるようにするための、包括的で動的に進化するフレームワークを目指しています。
SalesforceのEinstein 1 プラットフォームを使用すると、お客様は既存のLLMから選択するか、独自のモデルを持ち込んで独自のビジネスニーズを満たすことができます。ベンチマークを使用してCRMユースケースのモデルを選択することで、企業はより効果的で効率的な生成AIソリューションを導入できます。
Einstein 1 プラットフォーム
世界No.1のAI搭載型CRMだからできる、業務の効率改善。
Einsteinが、働くみなさんを応援します。


原文情報や著者にアクセスされたい方は下記をご参照ください。
原文 : Creating the World’s First LLM Benchmark for CRM
著者 : Peifeng Wang、Hailin Chen、Lifu Tu、Jesse Vig、 Sarah Tan 、 Bert Legrand 、Shafiq Rayhan Joty
コアチームメンバー : Peifeng Wang、Hailin Chen、Lifu Tu、Shiva Kumar Pentyala、Xiang-Bo Mao、Jesse Vig、 Sarah Tan、Bert Legrand、Shafiq Rayhan Joty
























